
최신 네트워크 아키텍처
딥러닝 모델이 학습에 실패했을 때, 가장 먼저 할 수 있는 일은 모델에 레이어를 추가하는 것이다.
특정 숫자 이상으로 레이어를 추가하면 기울기가 급격히 증가하거나 기울기 소실과 같은 문제가 발생한다.
이러한 문제는 가중치 초기화를 신중히 하거나 중간에 표준화 레이어를 삽입하면 부분적으로 해결할 수 있다.
ResNet
네트워크 레이어에 바로가기 연결을 추가하고 잔여 매핑을 명시적으로 지정해 이러한 문제를 해결한다.
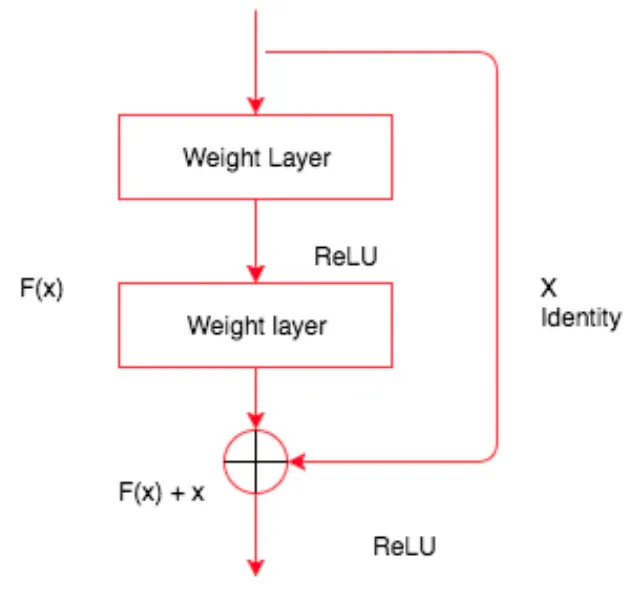
ResNet의 작동 방식
지금까지의 모든 네트워크에서는 서로 다른 레이어를 쌓아 입력이 출력에 대응되는 함수를 찾으려고 했다.
ResNet은 입력에서 출력으로의 기본 대응을 학습하는때신, 두 레이어 간의 차이를 학습한다.
이때 H(x)를 계산하려면 입력에 잔차를 추가하면 된다.
잔차는 F(x) = H(x) - x가 되다.
→ H(x) 를 학습하는 게 아닌 F(x) + x 를 학습한다.
각 ResNet 블록은 일련의 레이어와 블록 입력에서 블록 출력으로 추가하는 바로가기 연결로 구성한다.
입출력은 크기가 같아야 한다. 크기가 다를 경우에는 패딩을 사용할 수 있다.
인셉션
컴퓨터 비전 모델의 대부분 딥러닝 알고리즘은 필터 크기가 1 * 1, 3 * 3 , 5 * 5 , 7 * 7 인 필터로 컨볼루션 레이어나 맥스 풀링을 사용해 만든다.
Inception 모듈은 크기가 다른 여러 필터로 컨볼루션 연산을 수행하고, 모든 출력을 연결한다.
인셉션 모듈은 컨볼루션 레이어를 만들 때, 어떤 크기가 적합한지에 대한 고민을 해결해준다. 인셉션 모델에서는 여러 사이트의 필터를 한꺼번에 사용하기 때문에 어떤 필터가 더 효과적인지까지도 네트워크 모델이 학습한다.
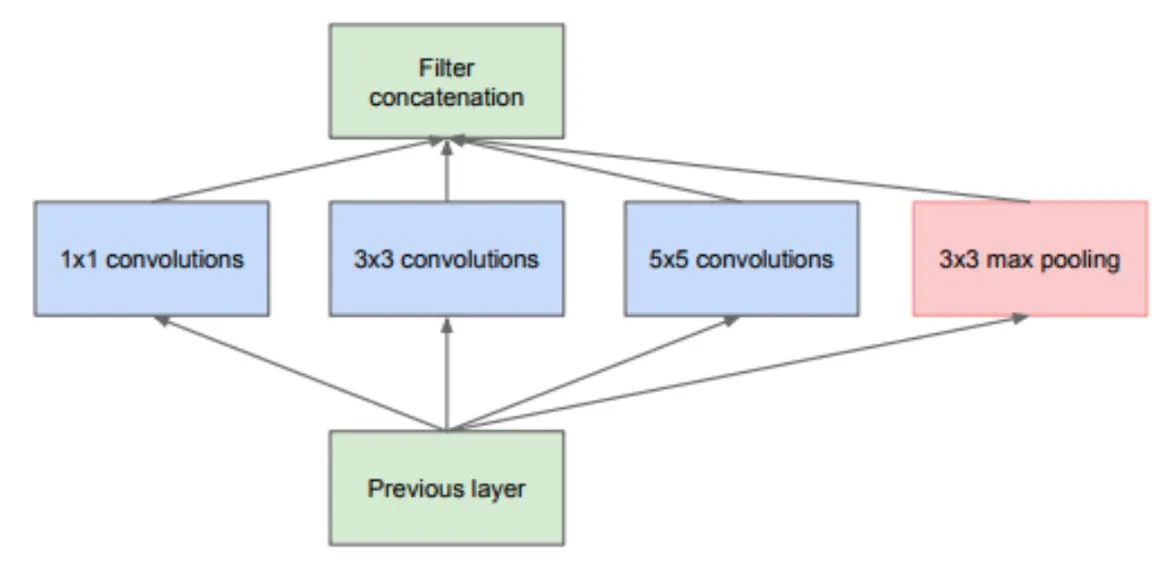
인셉션 모델

차원 축소 기법이 적용된 인셉션 모델
입력 데이터를 3 * 3과 5 * 5 컨볼루션에 통과시키기 전에 1 * 1 컨볼루션을 먼저 적용하는 인셉션 블록의 변형 형태가 일반적으로 사용된다. 이 변형된 인셉션 블록은 계산량의 병목 문제를 해결하는 데 유용하다
1 * 1 컨볼루션은 차원 축소의 역할을 담당한다. 1 * 1 컨볼루션은 한 번에 하나의 값을 채널에 통과시킨다.
입력 크기가 (10, 64, 64) 크기의 입력에 (10, 1, 1) 필터를 적용하면, 출력 크기는 (100, 64, 64) 가 된다.
DenseNet
ResNet은 더 깊은 네트워크를 지원하기 위해 바로 가기 연결을 사용한다.
DenseNet은 각 레이어가 그 다음의 모든 레이어에 연결되는 새로운 개념을 소개한다.
즉, 특정 레이어는 앞에 위치하는 모든 레이어의 피처 맵을 입력받게 된다.

DenseNet 아키텍처
DenseNet의 장점
•
필요한 파라미터 수를 상당히 줄일 수 있다.
•
vanish gradient 문제를 완화시킨다.
•
피처를 재사용할 수 있다.
앙상블 모델
여러 모델을 결합해 더 강력한 모델을 의미
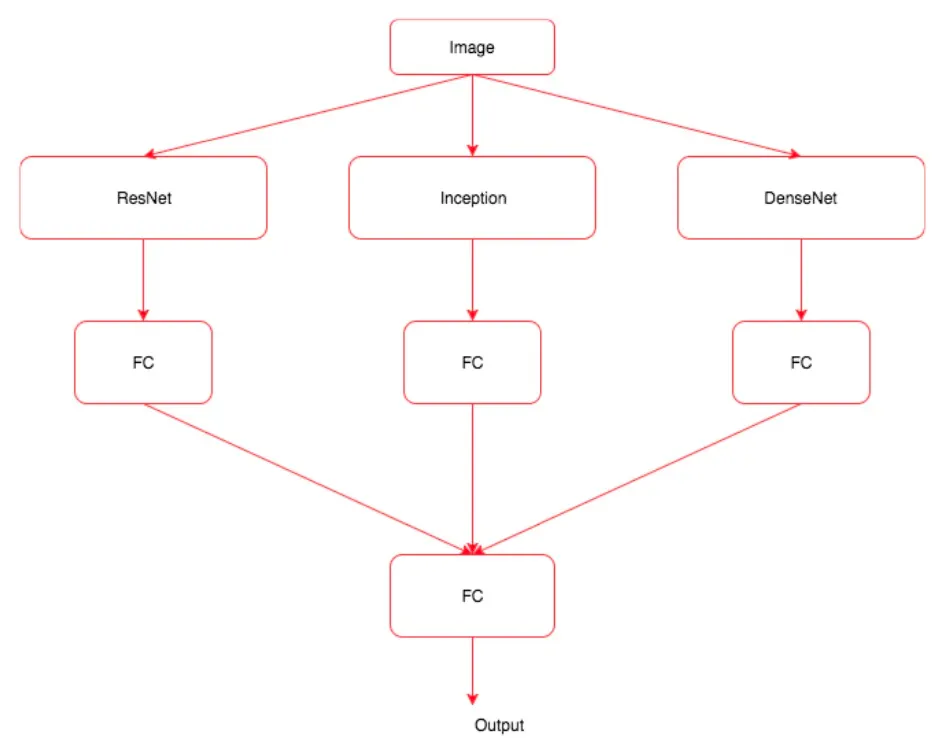
앙상블 모델 아키텍처
과정
1.
3개 모델 만들기
2.
생성한 모델을 이용해 이미지 피처 추출
3.
레이블과 함께 3가지 모델의 모든 피처를 반환하는 사용자 정의 데이터셋 생성
4.
위 그림 아키텍처와 유사한 모델 만들기
5.
모델을 학습시키고 검증
특장점
앙상블 모델은 강력하지만, 연산 비용이 많이 든다.
캐글같은 데이터 분석 경쟁 대회와 같이 문제를 해결할 때 사용하기 좋은 기법이다.
인코더-디코더 아키텍처
이전까지의 대부분 딥러닝 알고리즘은 학습 데이터를 해당 레이블에 매핑하는 모델이었다.
이 모델들은 시퀀스 데이터를 학습하거나 다른 시퀀스나 이미지를 생성하는 작업에는 적합하지 않다.
•
언어 변역
•
이미지 자막
•
이미지 생성
•
음성 인식
•
질문 답변 시스템
대부분 이런 문제는 sequence-to-sequence 매핑의 형태로 볼 수 있으며, 이는 인코더-디코더 아키텍처라는 아키텍처 형태를 사용해 해결할 수 있다.
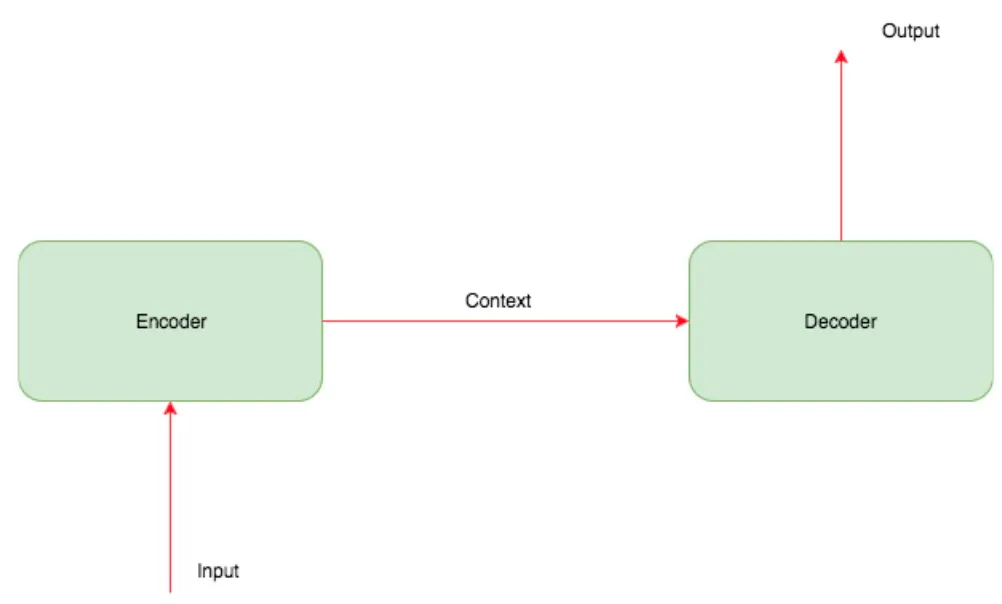
인코더-디코더 아키텍쳐
일반적으로 입력 데이터가 시퀀스 데이터일 경우 인코더는 RNN, 입력 데이터가 이미지 데이터일 경우 인코더는 CNN이다. 인코더는 입력받는 이미지 또는 시퀀스 데이터를 모든 정보를 보관하는 고정 길이 벡터로 변환한다.
디코더는 다른 RNN이거나 CNN이다.

이미지 자막 시스템을 위한 인코더-디코더 아키텍처
인코더
이미지 자막 시스템의 경우, 이미지에서 피처를 추출하기 위해 ResNet, 인셉션과 같은 사전 학습된 아키텍처를 사용한다. 앙상블 모델과 마찬가지로 선형 레이어를 사용해 고정된 벡터 길이를 출력한 후 해당 선형 레이어를 학습할수 있게 만든다.
디코더
디코더는 이미지에 대한 자막을 생성하는 LSTM 레이어이다. 간단한 모델을 만든다면, 입력으로써 인코더 임베딩을 LSTM에 한 번 전달한다. 그러나 이 경우에 디코더가 학습하기 꽤 어려울 수 있다.
따라서 디코더의 모든 단계에 인코더 임베딩을 제공하는 방식이 더 일반적으로 사용된다.
디코더는 입력된 이미지의 자막을 가장 잘 설명하는 텍스트 시퀀스를 생성하는 것을 학습한다.