
1. 자연어 처리의 주요 주제들
지식을 구성하는 수단으로 사용되어온 자연어는 정보를 담고 있다.
자연어가 포함한 정보를 다양한 목적을 위해 사용할 수 있는데, 예시는 다음과 같다.
1.
텍스트 분류/ 회귀 문제
-분류: 감정 인식, 추천/ 비추천
-회귀: 영화 리뷰에 따른 별점 평가, 문장 간 유사도 평가
2.
기계 번역
3.
빈칸 채우기
4.
질의 응답
5.
텍스트 요약
6.
문장 생성
2. 전처리
크롤링 등의 과정을 통해 얻은 모든 자연어 데이터는 필요에 맞게 전처리 해야 한다. 요리를 하기 전, 재료를 손질하는 단계와 같다. 손질이 되지 않은 재료를 사용할 수는 있겠지만, 좋은 요리가 되지는 못한다.
전처리의 과정은 크게 4가지로 구분한다.
1.
Tokenization(토큰화)
주어진 텍스트를 원하는 단위(토큰)로 나누어 저장하는 전처리 단계이다. 기본적으로 토큰화에서 토큰은 단어를 의미하지만, 문장으로 토큰화 할 수도 있다. 최근에는 단어보다 작은 단위로 토큰화 하여 성능을 높이기도 한다.
ex) Time is an illusion.Lunchtime double so! → [”Time”, “is”, “an”, “illusion”, “Lunchtime”, “double”, “so”]
토큰화를 어떤 기준으로 하는지 생각해보아야 하는 순간이 있다. 토큰화 기능을 제공하는 라이브러리들 간에도 의견 차이가 존재해 서로 다른 토큰화 결과를 반환하는 경우이다. 아래 예시처럼 하나의 단어를 여러 방식으로 토큰화 할 수 있는 경우를 말한다. 이때는 자신의 목적에 가장 부합하는 라이브러리를 선택해 전처리를 진행하면 된다.
ex) Don’t play with my Dondurma → [”Don”, “’t”]? [”Do”, “n’t”]
아래 코드는 라이브러리마다 위 예시를 어떻게 처리하는지 보여주기 위한 코드이다. 각각 차이가 있다는 것을 확인해 볼 수 있다.
from nltk.tokenize import word_tokenize
from nltk.tokenize import WordPunctTokenizer
from tensorflow.keras.preprocessing.text import text_to_word_sequence
print('단어 토큰화1 :',word_tokenize("Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop."))
print('단어 토큰화2 :',WordPunctTokenizer().tokenize("Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop."))
print('단어 토큰화3 :',text_to_word_sequence("Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop."))
단어 토큰화1 : ['Do', "n't", 'be', 'fooled', 'by', 'the', 'dark', 'sounding', 'name', ',', 'Mr.', 'Jone', "'s", 'Orphanage', 'is', 'as', 'cheery', 'as', 'cheery', 'goes', 'for', 'a', 'pastry', 'shop', '.']
단어 토큰화2: ['Don', "'", 't', 'be', 'fooled', 'by', 'the', 'dark', 'sounding', 'name', ',', 'Mr', '.', 'Jone', "'", 's', 'Orphanage', 'is', 'as', 'cheery', 'as', 'cheery', 'goes', 'for', 'a', 'pastry', 'shop', '.']
단어 토큰화3 : ["don't", 'be', 'fooled', 'by', 'the', 'dark', 'sounding', 'name', 'mr', "jone's", 'orphanage', 'is', 'as', 'cheery', 'as', 'cheery', 'goes', 'for', 'a', 'pastry', 'shop']
JavaScript
복사
2.
Cleaning(정제)
정제는 갖고 있는 코퍼스로부터 노이즈 데이터를 제거하는 것이다.
정제를 여러 방식으로 할 수 있는데 가장 간단한 방법은 소문자화이다. 영어의 경우 대문자와 소문자 구분이 있어, 이를 적절히 통합해줄 수 있어야 한다. 사랑을 뜻하는 love는 Love로 쓴다 하더라도 같은 의미를 지닌다. 따라서 대소문자를 통합할 필요가 있다. 하지만 무조건적인 대소문자 통합이 성능을 저하 시키기도 한다. 예를 들어 미국을 뜻하는 US와 우리를 뜻하는 us는 다른 의미로 사용되지만 대소문자를 통합하면 같은 의미로 인식된다.
불필요한 단어 제거도 정제 과정 중 하나이다. 등장 빈도가 너무 적으면 풀고자 하는 문제에 도움이 되지 않아 불필요한 단어로 고려해 제거한다. 또 영어에서 길이가 너무 짧은 단어는 불필요한 경우가 많아 제거하기도 한다.
정제는 불용어(stopword) 제거, 특수 문자 제거도 포함한다. 불용어와 특수 문자 모두 풀고자 하는 문제에 따라 다르게 처리하니 주의해야 한다. 예를 들어, the를 불용어에 넣는 경우도 있고 넣지 않는 경우도 있다.
*불용어 stopword: 분석에 안쓰이는 단어, 주로 큰 의미 없는 단어들
3.
Regularization(정규화) - Stemming & Lemmatization(어간 및 표제어 추출)
정규화는 표현 방법이 다른 단어들을 통합해 같은 단어로 만들어 준다. 정규화를 수행하는 방법은 어렵지 않다. 잘 정의된 토크나이저를 사용해 수행할 수 있다. 정규화 중 가장 대표적인 기법은 어간 추출과 표제어 추출이다.
어간 추출은(stemming) 의미 있는 단위를 추출하는 것이다. 규칙에 따라 형태적으로 변형하여 의미 있는 단위를 추출한다.
ex) 포터 알고리즘 Electrical → electric (~ical을 ~ic로 바꾸는 규칙에 따라 형태 변형)
표제어 추출은 기본 형태를 추출하는 것이다. 표제어는 다른 말로 ‘기본 사전형 단어’이다. 사전에 있는 기본 형태를 단어에서 알아내고 그것으로 변경하는 방법이다.
ex) am, are, is → be
4.
Padding
서로 길이가 다른 텍스트는 위 전처리 과정을 거친 후 토큰으로 저장했을 때, 서로 길이가 다를 수 있다. 이때 길이를 맞춰주는 것이 padding이다.
ex)
[”I”,“have”,”been”,”try”,”to”,”call”] 6개의 토큰
[”I”,“have”,”been”,”my”,”own”,”for”,”long”,”enough”] 8개의 토큰
>>패딩 이후>>
[”I”,“have”,”been”,”try”,”to”,”call”, “”, “”] 8개의 토큰
[”I”,“have”,”been”,”my”,”own”,”for”,”long”,”enough”] 8개의 토큰
1~4의 전처리 과정을 통해 정돈된 형태의 코퍼스를 얻게 된다. 이때 1~3을 tokenization으로 뭉뚱그려 표현하기도 한다. 여기까지가 자연어 전처리의 절차이다.
마지막으로 토큰화를 하는 또 다른 방식만 소개하면서 자연어 전처리에 대한 설명을 마무리 하겠다.
1-2. BPE
위 전처리 과정은 사전에 정해 놓은 몇 가지 규칙에 따라 토큰화 한다. 위 같은 토큰화 기능을 제공하는 라이브러리에서 사전 정의해 놓은 규칙이 부적절할 수 있으며, 영어에 대해서는 잘 작동하지만 그 외의 언어에서는 다른 규칙이 필요하다는 문제가 있다.
이때 BPE(Byte Pair Encoding)을 사용할 수 있다.
BPE는 데이터에 자주 등장하는 녀석을 하나로 압축하여 사용한다.
ex) Zizzi’szippy zipper zips → AzA’s Apy Apper Aps
이 예시를 보면 자주 등장하는 Zi를 A로 치환한 것을 볼 수 있다. BPE의 작동 방식은 다른 말로 통계적으로 출현 확률이 높은 것을 하나의 토큰으로 취급하는 방식이다. Z와 i가 자주 같이 쓰이기 때문에(동시에 출현할 확률이 높기 때문에) 하나로 압축해버리는 것이다.
BPE를 사용하면 유니코드 등 다른 언어에 완벽하게 대응할 수 있다.
3. 언어 모델
언어 모델은 단어 시퀀스에(문장) 확률을 할당하는 방법이다. 한 문장의 확률이 다른 문장의 확률보다 높다면, 그 문장이 더 나은 문장이라 판단할 수 있다. 예를 들어, 기계 번역을 결과로 출력하기 더 적절한 문장을 고른다고 해보자.
A: 나는 버스를 탔다
B: 나는 버스를 태운다
A 문장과 B 문장 중 더 적절한 문장을 고르기 위해 확률을 이용하는 것이다.
P(나는 버스를 탔다) > P(나는 버스를 태운다)
A 문장의 확률이 B 문장의 확률보다 높아 더 적절하다고 판단이 가능하다.
이러한 쓰임을 위해 언어 모델을 사용하며, 기계 번역 외에도 오타 교정, 음성 인식 등에서도 활용 가능하다.
언어 모델은 2가지로 구분된다. 통계를 이용하는 전통적인 방법과 인공 신경망을 이용하는 방법으로 나눌 수 있다. 최근에는 인공 신경망을 이용한 방법이 GPT, BERT와 같은 자연어 처리 기술에 활용되며 더 좋은 성능을 보여주고 있다.
1.
전통적 방법(통계적 방법)
a.
카운트 기반의 접근
문장의 확률을 계산할 수 있어야 언어 모델을 만들 수 있다.
"I am a boy"라는 문장의 확률은 다음과 같다.
각 단어의 등장 확률을 구하는 기본적인 방법은 등장 횟수를 카운트 하는 것(세는 것)이다.
만약 데이터에서 I am a 다음에 boy가 100번 중 40번이 나왔다면 p(boy | I am a)는 40%이다.
카운트 기반의 방식은 데이터(corpus)에 없는 문장에 대해서 확률을 정의할 수 없다는 한계가 있다.
b. N-gram
N-gram 방식은 카운트 기반의 한계를 보완해줄 수 있다.
한 단어의 확률을 구할 때 N-1개의 이전 단어만을 활용한다.
N이 1, 2, 3일 때를 각각 uni-grams, bi-grams, tri-grams라 한다. 이들로 예를 들어보면
uni-grams일 때에는 0개의 이전 단어를 활용한다.
bi-grams일 때에는 1개의 이전 단어를 활용한다.
*sos = start of a sentence(bos =beginning of a sentence라고 사용할 수도 있다.)
tri-grams일 때에는 2개의 이전 단어를 활용한다.
2.
인공 신경망을 이용한 방법
4. 워드 임베딩
일반적으로 one-hot encoding 방식으로 단어를 표현한다.
["I", "am", "a", "boy"]라는 코퍼스에서 "I"를 [1,0,0,0], "boy"를 [0,0,0,1]로 표현하는 등의 방식으로 표현하는 것이다. 이러한 방식은 2가지 단점을 가진다. 사용 단어가 많으면 많을수록 희소 해져 공간을(컴퓨터 자원) 비효율적으로 사용하게 된다. 또 단어 벡터 간의 유사도를 반영하지 않는다. 예를 들어, 빨강, 분홍, 파랑 세가지 단어를 임베딩 하였을 때, 각각 [1,0,0], [0,1,0], [0,0,1]로 될 뿐이다. 분홍은 파랑보다 빨강에 가까운 의미를 지니는데, 그 점을 반영하지 못한다. 그래서 단어 간 유사도를 이용해 단어를 단어 벡터로 만드는 것이 워드 임베딩이다.
a.
word2vec
word2vec은 단일 레이어 퍼셉트론을 이용한 워드 임베딩 방식이다.
단어 벡터 에 대해를 취함으로 얻을 수 있다는 뜻이다.
두 가지 방식이 있는데, 다음과 같다.
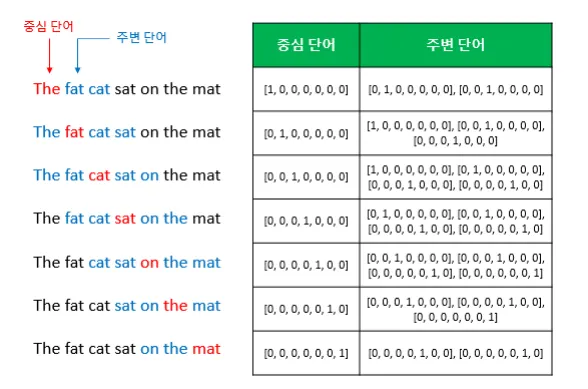
a-1)CBOW(Continuous bag of words)
주변에 있는 단어들을 입력으로 중간에 있는 단어를 예측하는 방식으로 학습한다.
연산을 그림으로 표현하면 다음과 같다.
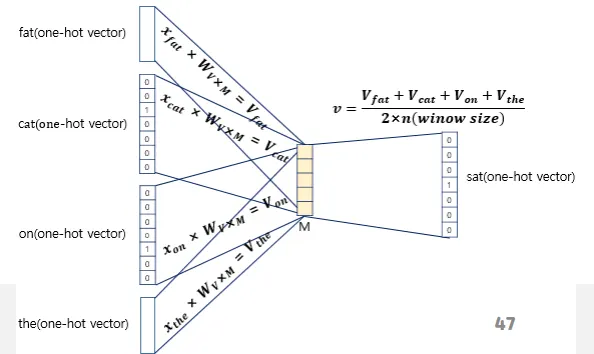
이 도식은 입력층, 투사층, 출력층으로 나누어 살펴볼 수 있다.
입력층에는 주변 단어의 one-hot 표현이 입력된다. 투사층에서는 입력층의 값에 W를 곱한 값을 받아 이들의 평균을 구한다. 출력층에서는 투사층의 값에 W’을 곱해주고 softmax를 취한다. 출력층의 값을 이용해 backpropagation을 통해 학습을 진행할 수 있다.
W와 W’을 각각 혹은 함께 임베딩 벡터로 사용한다.
a-2)Skip-gram
Skip-gram 은 CBOW 와 반대로 중심 단어로부터 주변 단어를 예측한다.
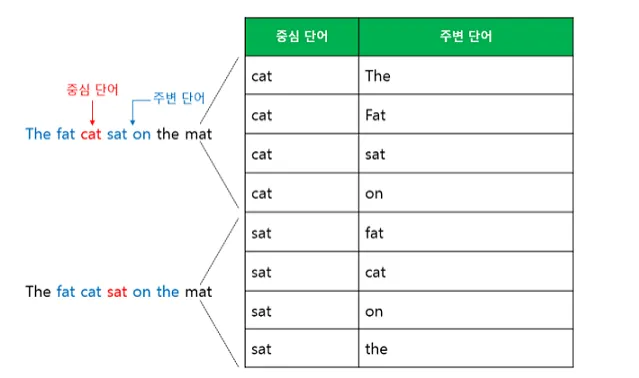
아래 도식은 Skip-gram이다. many-to-1이 아니라 1-to-many이기 때문에 CBOW보다 난이도가 높지만, 일반적으로 더 좋은 성능을 보인다.
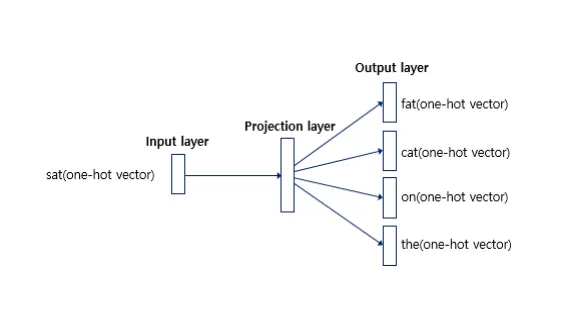
W’이 2개 이상인 것처럼 보이지만 실제로는 하나 이다.