
1. Introduction
•
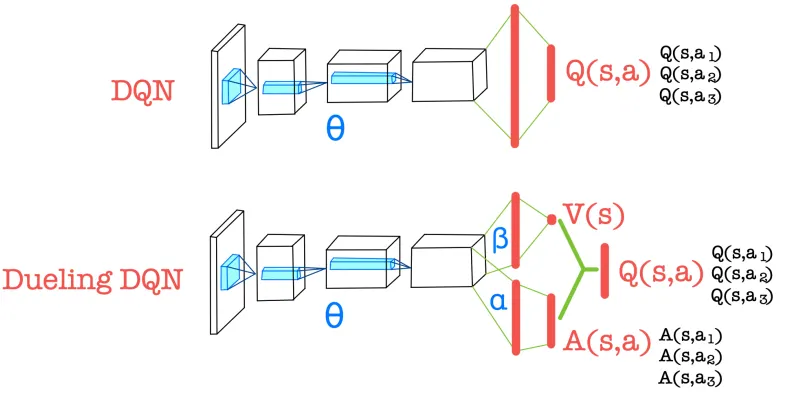
Compute the advantage function and the state-value function separately, then combine them to obtain the action-value function.
•
The CNN encoder is shared, while only the parameters of the fully connected layers differ for each function.
•
Useful for evaluating the state value even when the action is not significant in the environment.
2. Value function
•
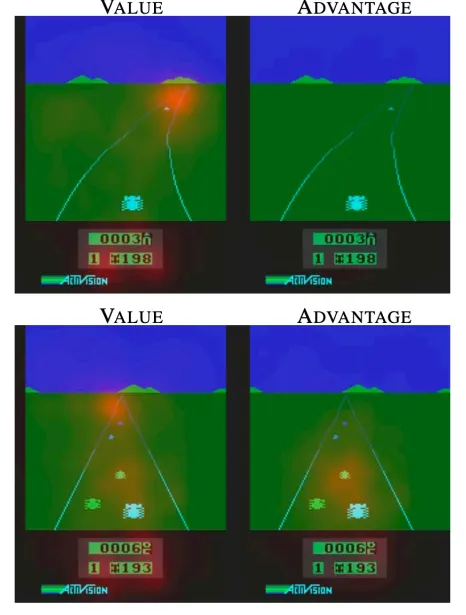
When actions have little influence on the environment in a given state, learning becomes more important for accurately evaluating the state value.
•
When actions have little influence on the environment in a given state, learning becomes more important for accurately evaluating the state value.
•
First case (the car is at a distant position)
◦
The importance of action selection decreases.
◦
Only when computing the state value, the car in front is considered.
•
Second case (the car is at a close position)
◦
The choice of action becomes more important.
◦
Each nearby car is also taken into account when computing the advantage.
3. Identifiability issue
•
The relationship among the Action value function, Advantage function, State value function
•
In Dueling DQN separate networks are used to compute the state-value function and the advantage function.
◦
The decomposition of a single Q-value is not uniquely defined.
▪
▪
, can’t be regarded as a good estimator.
•
Approach 1) Add an advantage function term for the optimal action.
◦
For the optimal action, the following property holds.
◦
◦
Since the max term has high variability, it reduces stability.
•
Approach2) Subtract the mean
◦
◦
For the optimal action, an error equal to the difference between the max and the mean occurs.
▪
The objective is to find the action that maximizes
▪
This is equivalent to maximizing the term composed of the advantage function.
▪
Whether the max or the mean is subtracted does not affect policy determination.
▪
This is because the state-value function does not vary with the action.