
1. RNN에 기반한 seq2seq의 문제점
기계 번역, 챗봇 등의 task를 해결하기 위해 seq2seq 모델을 사용했다. seq2seq는 RNN의 기반한 모델이기 때문에, 기존 RNN이 가지고 있는 문제점 또한 가지고 있다. RNN이 가진 정보 혼탁 문제를 seq2seq도 겪게 된다. seq2seq의 인코더가 정보를 압축하는 과정에서 초반에 입력된 시퀀스 정보가 손실 된다.
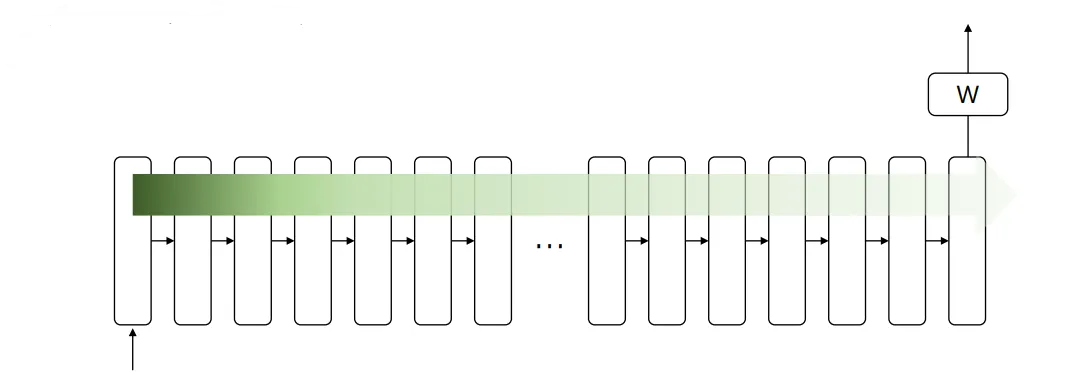
이 그림을 seq2seq의 인코더로 보면 이해가 쉬울 것이다. 처음 입력된 시퀀스의 정보가 출력 되는 부분까지 온전히 전달되지 못하고 희미해진다. 정보의 손실이 일어나는 것이다. 이러한 문제를 해결하기 위해 사용하는 것이 Attention이다.
2. Attention mechanism
Attention mechanism을 그림으로 먼저 보고 가겠다.
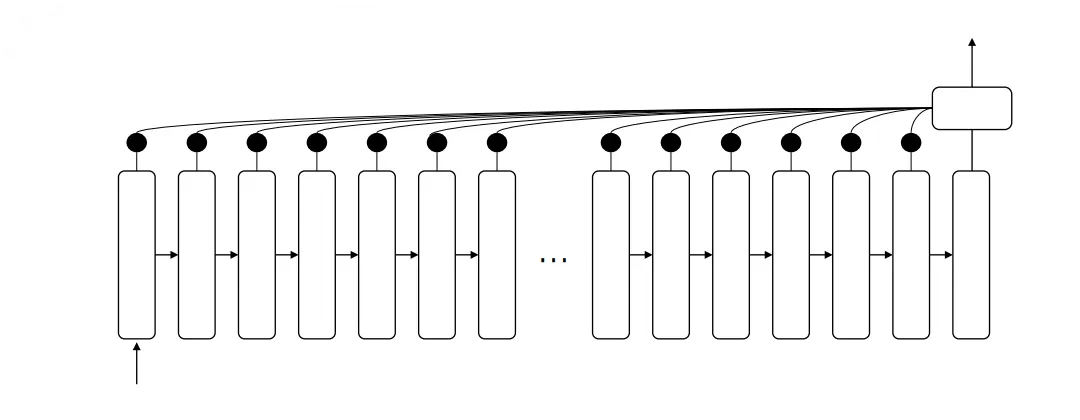
출력하는 부분과 이전 노드들을 연결해 놓은 것을 확인할 수 있다. 이전 노드들과의 연결을 통해 정보 손실을 막는 것이 Attention mechanism의 핵심 아이디어 이다.
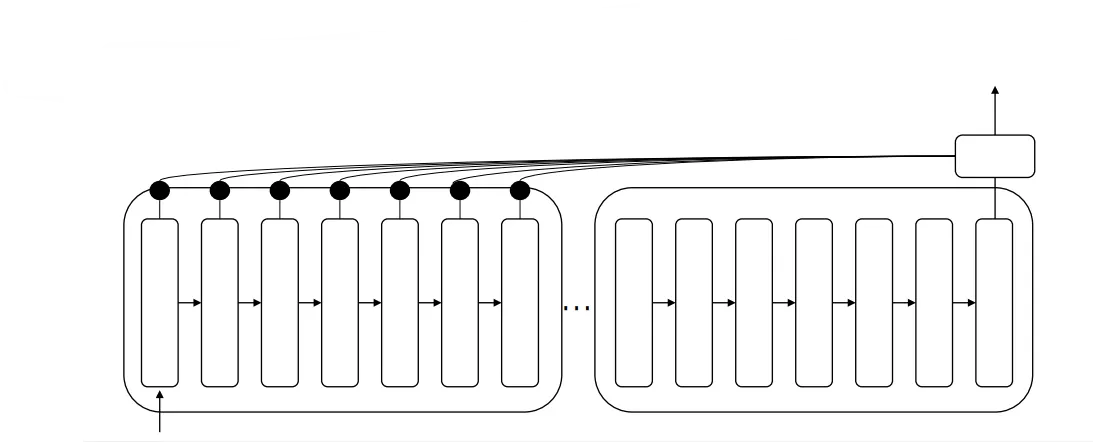
seq2seq에 Attention mechanism을 적용하면 위와 같다. 인코더의 정보를 디코더에서 손실 없이 사용할 수 있도록 디코더의 출력 부분과 연결한다. Attention mechanism을 적용하기 이전엔 디코더가 받을 수 있는 정보는 인코더의 출력 값 뿐이었다. 앞서 설명 하였던 것처럼, 그 출력 값이 초반에 입력된 시퀀스들의 정보를 온전히 담아내지 못한다. 그 문제를 위 방식을 통해 해결할 수 있다.
seq2seq에 Attention이 어떻게 적용되는지 더 자세히 보겠다. 3가지 단계를 거쳐 적용할 수 있다.
1.
Attention score 계산: 인코더의 hidden state의 각 값이( …) 얼마나 중요한지 계산한다.

Attention score를 계산하는 여러 방법이 있다. 여기에서는 내적의 의미를 지닌 dot을 사용해서 Attention score를 계산하는 것에 대해 설명하겠다. 내적은 두 벡터의 유사도를 측정하는 용도로 사용할 수 있다.
디코더에서 계산 중인 값의 벡터 와 가장 유사한 hidden state를 알아와 사용하기 위해 두 벡터 와 를 내적한다. 수식으로는 다음과 같이 표현 가능하다.
2.
Attention weight 계산: Attention score에 softmax를 적용해 합이 1인 weight 분포를 만들어낸다.
Attention weight는 Attention score에 Softmax를 적용하기만 하면 된다.

3.
Context vector 계산: Attention weight를 인코더의 hidden state에 곱한 값을 더해 계산한다.
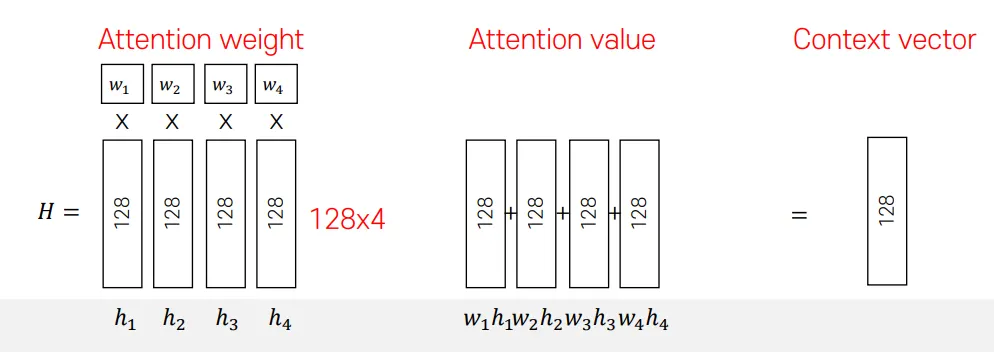
정리하면서 수식으로 표현하도록 하겠다. 위 단계들을 수식으로 나타내면 다음과 같다.
*
*
*
이 과정을 통해 얻은 Context vector는 다음과 같이 사용한다.
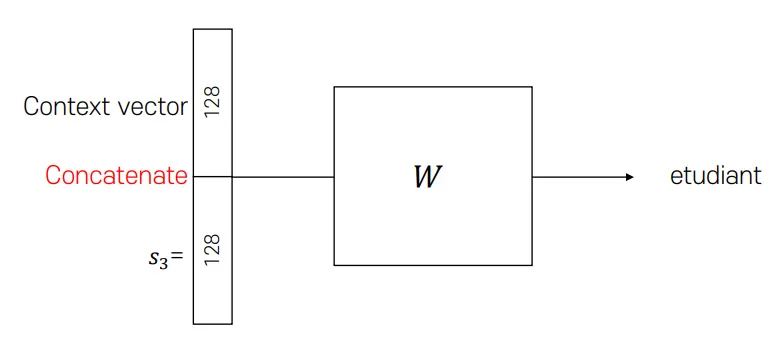
현재 시퀀스 벡터와 Context vector를 Concatenate하여 사용할 수 있다.
3. Transformer
Transformer에선 Query, Key, Value라는 새로운 용어가 등장한다. Attention을 설명할 때, 사용했던 와 연관이 깊다.
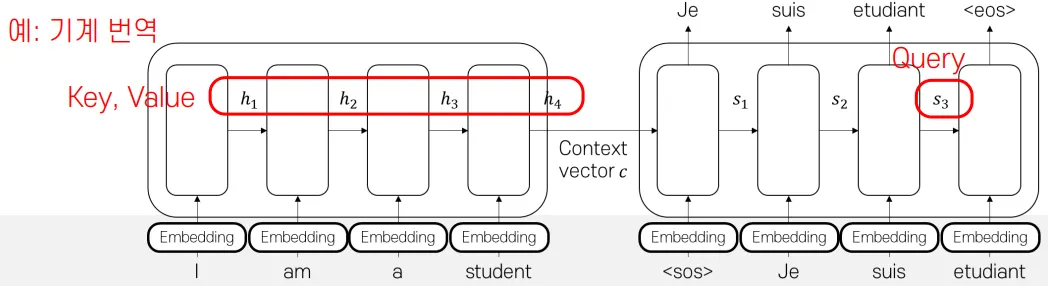
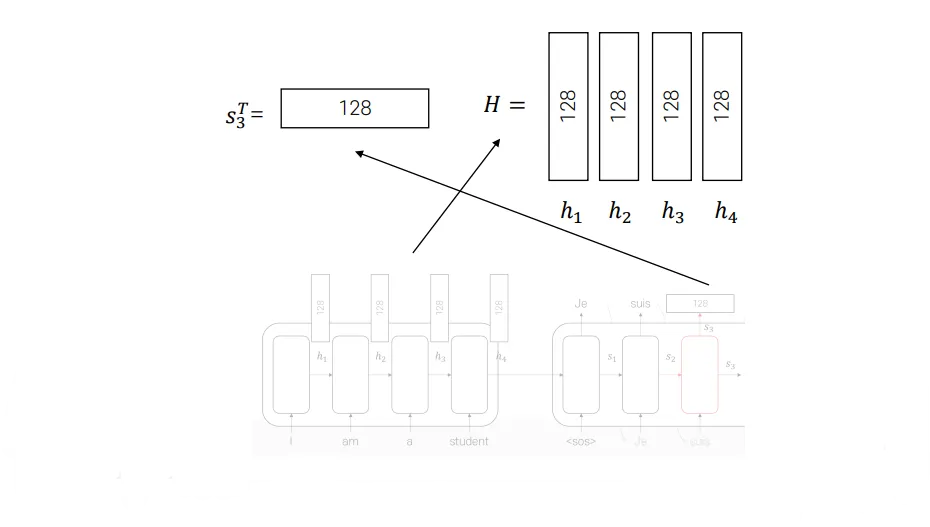
위 도식은 Attention을 이용하는 seq2seq 기계 번역의 경우다. I, am, a, student라는 단어들을 받아서 인코더, 디코더에서 순차적으로 처리한다. 앞서 설명했던 것처럼 인코더에서는 입력의 정보를 압축하고 디코더에서는 단어들을 생성한다. etudiant를 생성하기 위해 suis를 Embedding한 값과 를 받는다. 와 H(=h1, h2, h3, h4)를 곱해 유사도를 계산하고, softmax를 취한 후 각 단어들에(H) 곱해 Context vector를 얻었다. 여기까지는 앞서 설명한 내용이다.
여기서 가 Query이고 H(=h1, h2, h3, h4)가 Key이다. 에 곱해진 단어들이 Value이다. 위 그림의 경우 Key와 Value가 같지만 다른 경우도 있다. 설명한, Context vector를 구하는 과정을 Query, Key, Value 용어로 바꾸면 다음과 같다.
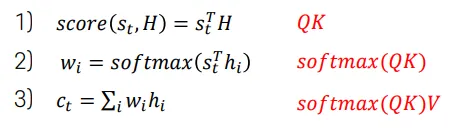
Transformer는 두 가지 특징을 가진다.
1. Self-Attention을 사용한다.
위에서 설명한 Q는 디코더에서, K와 V는 인코더에서 나온 값이다. 만일 Q,K,V가 한 곳에서만 나온다면, self-attention으로 볼 수 있다. self라는 단어를 보면 이해가 쉽다. 다른 것의 개입 없이 혼자 처리하겠다는 것이다. 오로지 인코더의 값만 사용하거나, 오로지 디코더의 값만 사용한다면 self-attention이다.


2. RNN 없이 self-attention + MLP 쌓아서 자연어를 인코딩 한다.
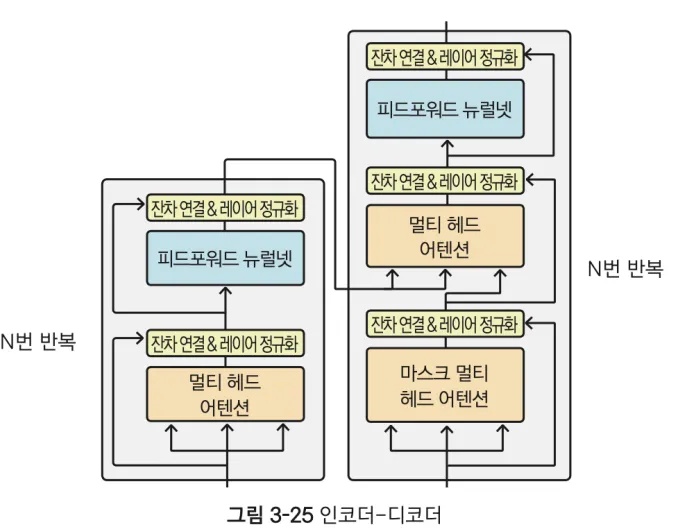
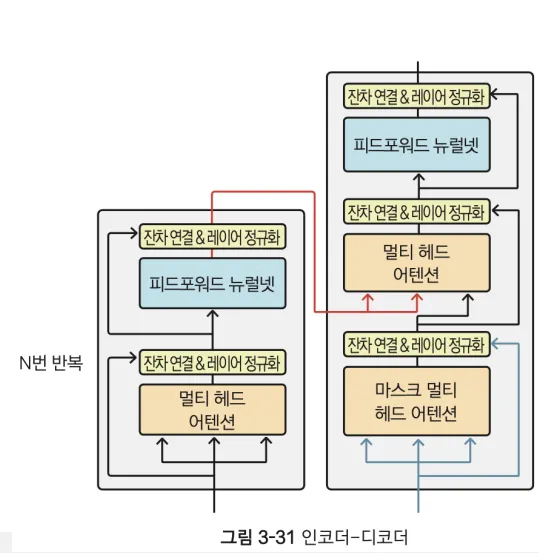
Transformer는 RNN 없이 self-attention과 MLP만을 이용하는 특징을 가진다. 위 그림은 Transformer의 구조도이다. 왼쪽 구조물이 인코더이고, 오른쪽 구조물이 디코더이다. 각각이 ‘멀티 헤드 어텐션’이라는 네트워크를 가지고 있다. 이는 앞서 설명한 self-attention이다. 인코더와 디코더의 결합부를 잘 봐두어야 한다. 아래 그림을 통해 결합부에 대한 이해를 높여보겠다.
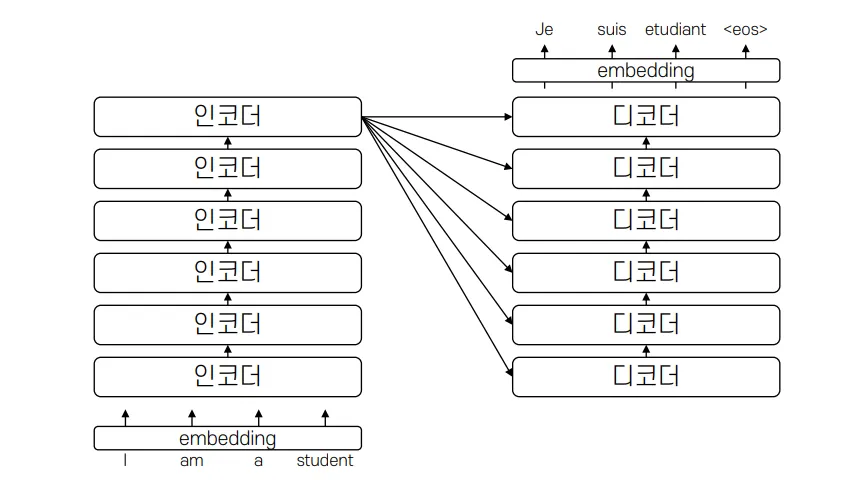
이처럼 마지막 인코더가 생성한 정보를 모든 반복되는 디코더가 똑같이 가져간다. 한 가지 더 주의해서 보아야 하는 부분이 있다. 위 그림을 보면 ‘I am a student’가 각각 x1, x2 …로 들어가면 RNN처럼 처리하는 것이 아닌지 의문이 들 수 있다. 하지만 각각 따로 들어가는 것이 아니라 통째로 들어가기 때문에 본질적으로 차이가 존재한다.
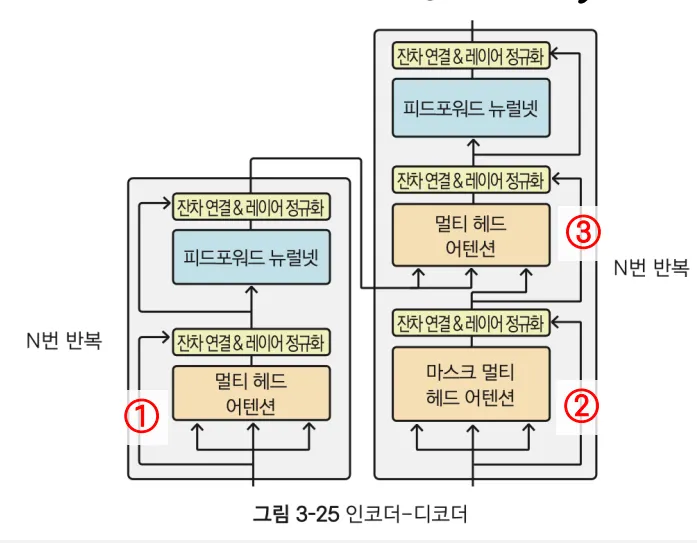

위 표처럼 Transformer의 구조는 세 가지의 self-attention을 사용한다. 인코더가 하나, 디코더가 둘을 가지고 있다. 각각 멀티 헤드 어텐션을 가지고 있고, 디코더는 멀티 헤드 어텐션 이전에 마스크 멀티 헤드 어텐션을 이용한다. 디코더가 가진 멀티 헤드 어텐션은 인코더가 전달하는 정보와 디코더가 만들어낸 정보를 동시에 처리한다.
이제 기본적인 구조를 알게 되었는데 추가적으로 입력값의 처리를 조금 더 자세히 보아야 한다. RNN의 경우 시간축에 따라 데이터를 처리했는데, 트랜스포머는 시간축에 대한 정보가 없다. 시간에 대한 정보를 넣어주기 위해 Positional Encoding이라는 것을 한다.
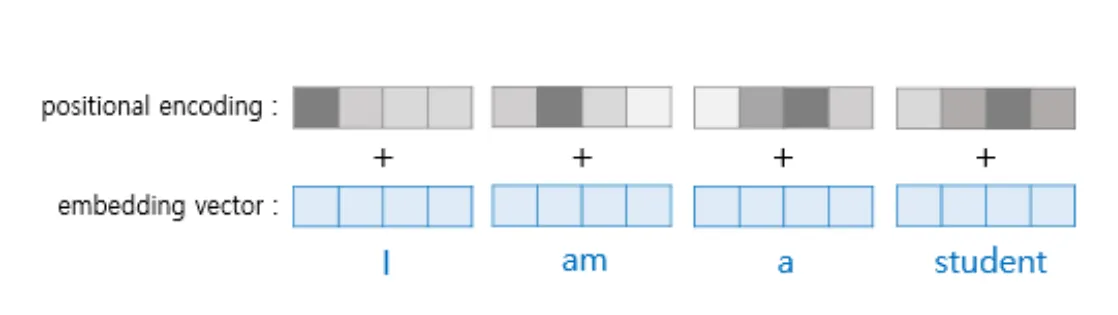
positional encoding은 다음과 같이 할 수 있다. 각각의 embedding vector와 시간 정보를 가진 positional encoding vector를 더해 사용한다. positional encoding 값은 sin, cos 삼각함수를 이용해 구할 수 있다. -1~1 사이의 값을 가지는 주기 함수이기 때문에 너무 커지지 않고 매 n번째의 토큰의 값이 같기 때문이다.
위 self-attention 세 가지를 하나씩 살펴보겠다.
1) (인코더 1층) 인코더의 self-attention
실제 멀티 헤드 어텐션에 대해 말하기에 앞서 self-attention에 대해 말하고 들어가려 한다.
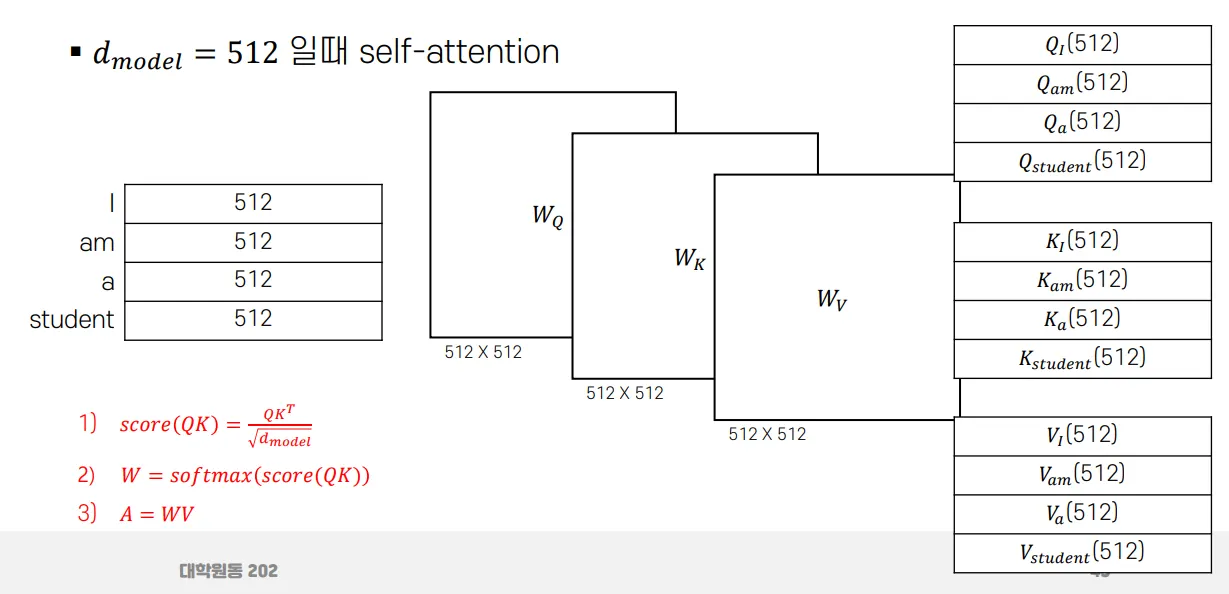
앞에서 살펴본 self-attention 수식에 따라 처리하려면, Q,K,V 각각에 대한 가중치가 존재해야 한다. 위처럼 가중치를 만들고 그를 활용한다.
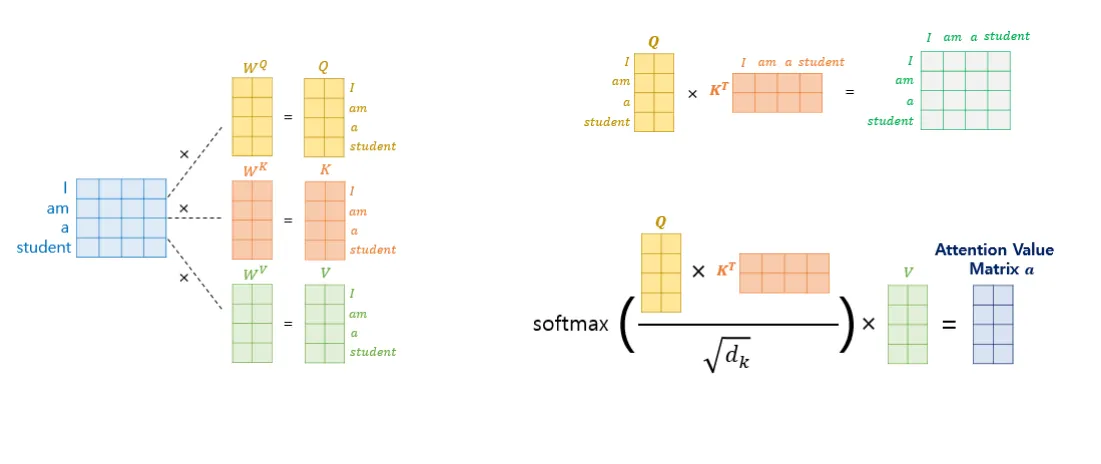
그 계산은 이처럼 각각을 처리한다. 이때 행렬을 이용해 한번에 처리할 수 있다. softmax안에 Q X 를 로 나누어 준다. 이는 해당 값이 너무 커져 발산하는 것을 막기 위함이다.
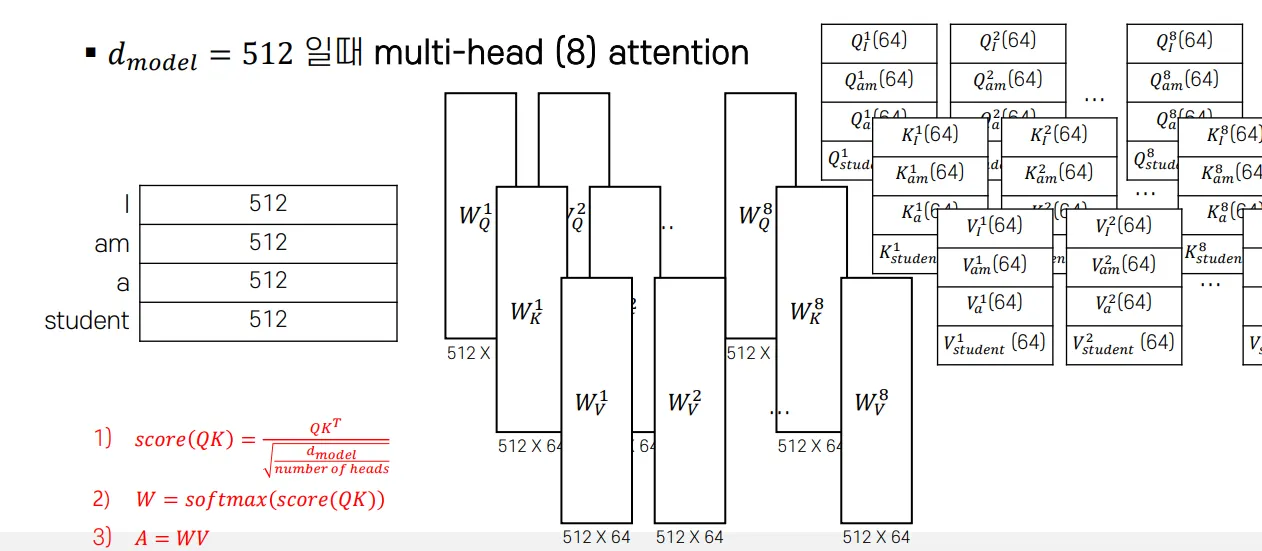
멀티 헤드 어텐션에 적용하면 이와 같다. 아까는 Q,K,V 각각 가중치 한 덩어리 씩 보여주었는데, 각 덩어리가 쪼개진 모습을 가지고 있다. 512x512 가중치 행렬 하나를 섰었다면, 여기서는 512x64 여러개를 사용한다.
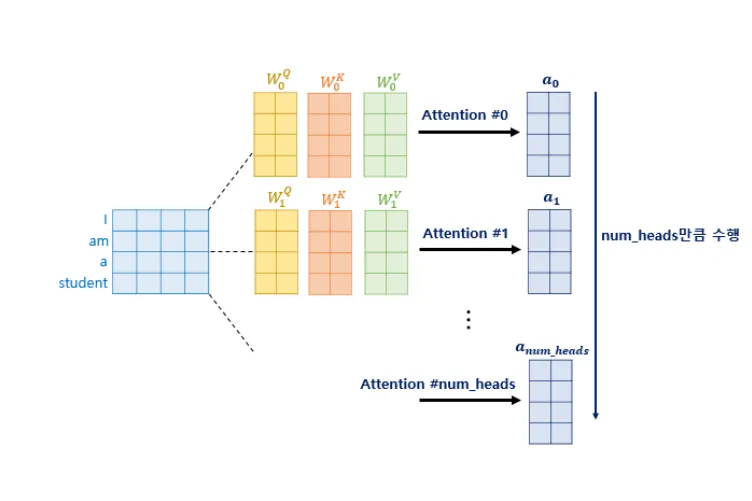
앞선 self-attentio과 마찬가지로 행렬을 이용해 한방에 처리 가능하다.
2) (디코더1층) 디코더의 self-attention
인코더의 self-attention과 동일하다. 하지만 한가지 유일하게 다른 점이 있는데, 마스킹을 한다는 점이다. 마스킹은 미래에 대한 정보가 같이 고려되는 현상을 막기 위해 진행한다.
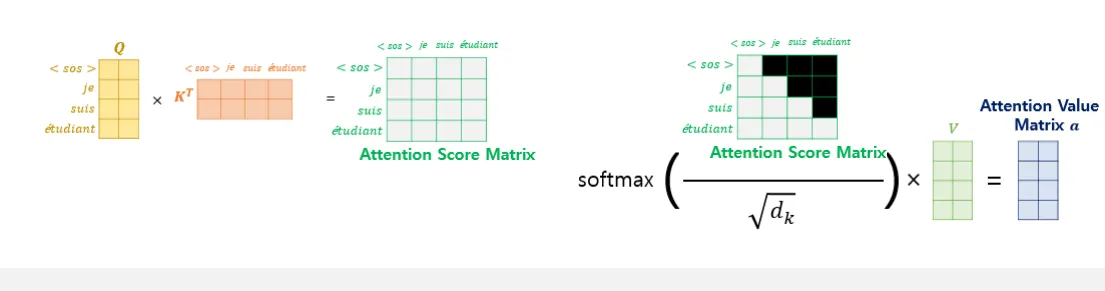
다음과 같이 마스킹을 진행해 미래 정보가 같이 고려되는 것을 방지한다.
3) (디코더2층) 디코더의 self-attention
위 1층 self-attention들은 각 어텐션 네트워크에 들어오는 Q,K,V의 소스가 같았다. 하지만 디코더 2층에서는 인코더, 디코더에서 각각 소스를 제공한다. Query는 디코더에서 만들어낸 정보를, Key, Value는 인코더에서 나온 정보를 이용합니다.