
1. Machine Learning algorithm categories
•
Supervised Learning
◦
지도 학습은 Label (정답)이 포함된 training data로부터 학습이 진행
◦
입력 데이터에 대해 회귀와 분류를 위한 규칙을 찾음
◦
Test data에 대해 예측을 진행
•
Unsupervised Learning
◦
비지도 학습은 Label이 없는 training data로부터 학습을 진행
◦
데이터에 내재된 구조를 파악하는 것이 목적임
◦
예) Clustering, PCA
•
Reinforcement Learning
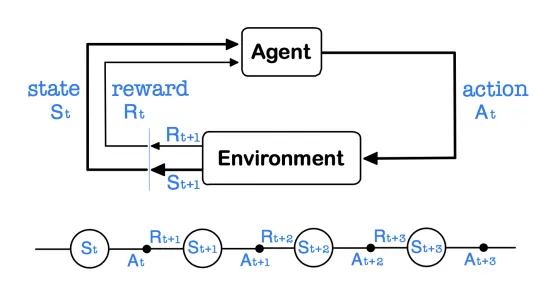
◦
강화학습은 sampled data가 존재하지 않으며, agent가 환경과 상호작용하며 얻게 되는 데이터를 바탕으로 학습 진행
◦
학습과정에서 agent는 각 state에서 policy를 기반으로 action을 선택하며 그 결과 reward를 얻음
◦
총 reward를 최대로 하는 policy를 찾는 것을 목적으로 함
2. RL을 사용하는 이유
•
노면에서 로봇 걷기 시스템 학습 가정
◦
지도학습
▪
입력 데이터: 로봇의 현재 관절 상태 (ex. 관절의 각도) 와 현재 노면의 굴곡이고
▪
Label(정답값)은 로봇이 넘어지지 않고 제대로 걷기 위한 다음 관절 상태
▪
(현재 관절의 각도, 현재 노면의 상태)-(정답 관절 상태) 쌍을 모델의 입력값으로 넣어야 함
⇒ 가능한 쌍의 개수가 상당히 많아지므로 모든 상태를 고려할 수 있는 데이터를 수집하여 학습을 하는 것이 어렵다.
◦
강화학습
▪
action: 앞으로 선택할 관절의 상태
▪
state: 현재 노면과 관절의 상태
▪
agent가 스스로 다양한 시도를 통해 적절한 action을 선택할 수 있음
⇒ 학습이 효율적으로 이뤄질 수 있다.
3. Deep Learning
•
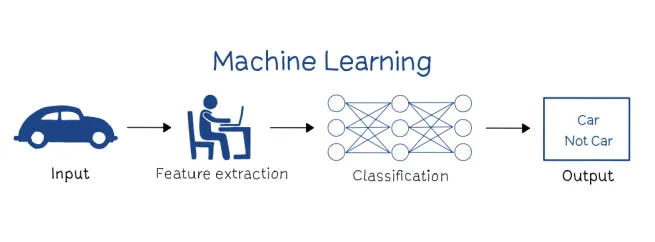
Machine Learning
◦
머신 러닝은 인간이 직접 데이터 전처리 과정을 수행해야 한다
◦
단점 : 인간이 데이터의 특성을 완벽히 파악하는 것이 어렵다.
⇒ 전처리된 데이터가 불완전하거나 특정 특징에 집중된 형태를 가질 수 있다
•
Deep Learning
◦
딥러닝은 머신러닝과 다르게 데이터 전처리 과정이 존재하지 않는다.
◦
모델이 raw data로부터 특징 추출

4. Deep Reinforcement Learning
•
로보틱스 분야
◦
State space가 지수함수적으로 늘어난다 (curse of dimensionality).
◦
이때 DL을 적용하게 되면, 높은 차원의 데이터로부터 자동으로 낮은 차원의 특징을 추출할 수 있다.
◦
예를 들어 CNN을 적용하여 이미지를 feature vector로 변환하고 fully connected layer에서 value function을 계산하는 방식으로 DRL을 활용할 수 있다.