
* Reference
•
강의자료
•
참고서적

1. Preface
Why is RL(Reinforcement Learning) interesting?
“머신러닝”은 지도학습, 비지도학습, 강화학습의 세가지 대분류로 나눌 수 있다고
하지만 강화학습은 다른 두가지 분류와는 결이 다르다.
친절하게 정답 혹은 라벨(Label)이 포함된 데이터를 떠먹여 주듯 학습시키는 지도학습,
정답이 포함되지 않은 불친절한 데이터에서 패턴을 발견하여 정보를 얻어내는 것을 비지도학습이라고 한다면
이 두 머신러닝 방법은 학습하는데 있어 분석의 대상이 되는 데이터가 주어져야 한다는 공통점이 있다고 할 수 있다.
강화학습은 이들과는 다르게 현재의 상태(State)에서 어떤 행동(Action)이 최선인지를 학습하며, 이때 최선의 행동이란 환경으로부터 주어지는 보상(Reward)을 최대화하는 행동을 의미한다. 예컨대 애완견에게 “앉아”를 훈련시키는 상황에서, 간식이라는 보상을 최대화 하기 위해 앉으라는 명령에 따라 애완견이 앉는 행동을 하게 된다면 이를 강화학습이라고 부를 수 있는 것이다.
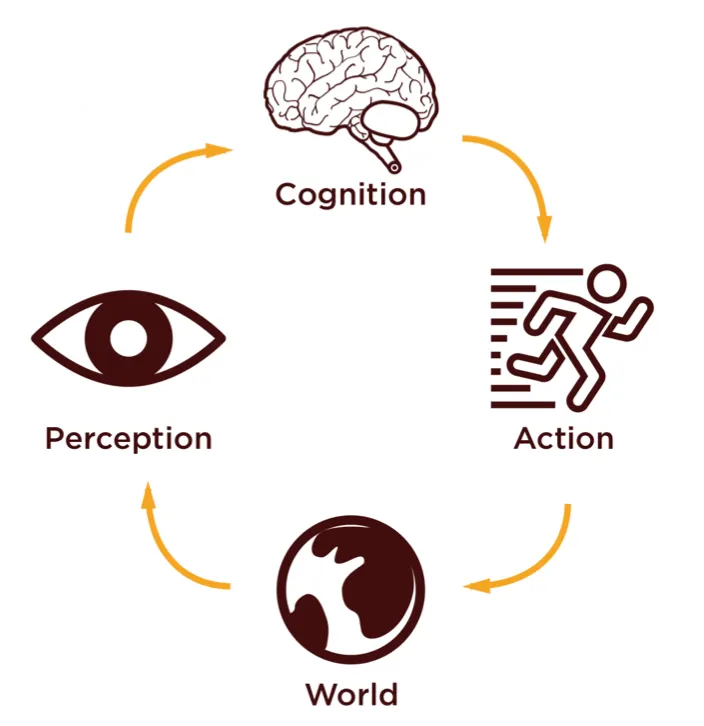
세상을 감각적으로 인지하여 뇌에서 지각하고 행동으로 이어진다는 생물의 행동 방식은 강화학습의 모티브가 된다.
강화학습은 생물의 지능과 밀접하게 맞닿아 있다. 뇌의 활성화 정도를 전극을 꽂아 측정하지 않는 이상 행동은 지능을 측정하는 거의 유일한 지표이며, 따라서 최적의 행동을 학습시키는 강화학습은 생물의 지능을 모방하고 구현하는데 있어 핵심적인 도구가 된다.
3. Formalizing RL
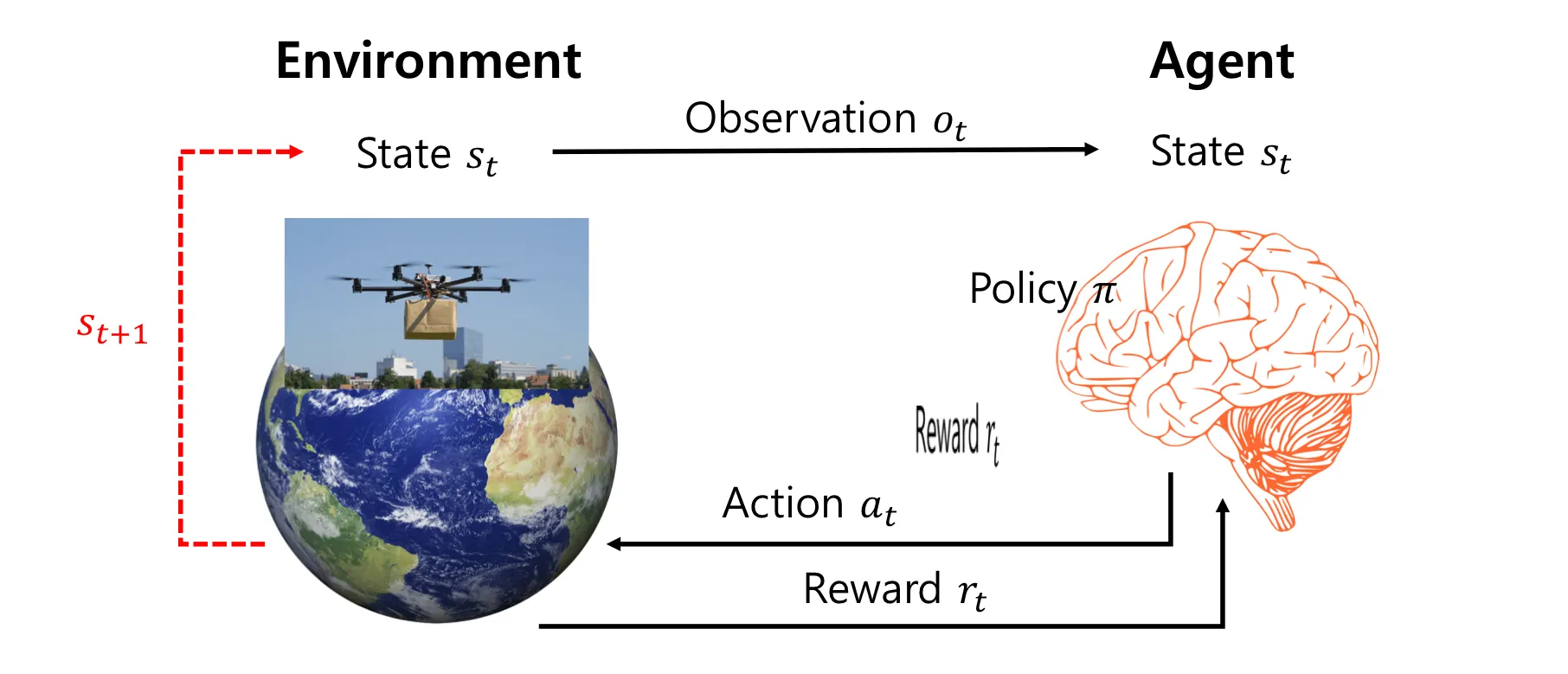
강화학습이 동작하는 과정이 그림으로 표현된 것. Reward, State, Policy, Value 등 강화학습에서 사용되는 용어 각각의 의미와 수식을 살펴볼 것이다.
강화학습의 구성성분은 크게 두개로 나눌 수 있는데, (1)행동의 주체인 에이전트(Agent)와 (2)보상을 주고 상태변이를 일으키는 주체인 환경(Environment)이다. 에이전트를 제외한 모든 것을 환경이라고 봐도 된다.
이때 환경은 데이터의 형태가 다양하고 연속적이며 정제돼있지 않기 때문에 환경을 입맛대로(?) 가공한 것을 상태(State)라고 한다. 이 정형화되고 이산적인 상태 정보를 이용해 학습을 하게 되며, 예를 들어 사진, 센서 신호나 위치 정보등을 상태의 예시로 들 수 있다.
에이전트는 행동을 통해 환경을 변화시키며, 환경은 행동에 대한 아웃풋으로 보상(Reward)과 변이된 상태(를 반환하여 에이전트를 변화시킨다(정확히는 에이전트 내부의 정책을 변화시킨다.). 에이전트와 환경은 순환적으로 서로를 변화시키는 관계인 것이다.
Reward
•
보상을 의미하는 스칼라 값.
•
한 에이전트가 어떤 행동을 했을 때 받게 되는 피드백 신호로서, 목적에 부합하는 행동일 수록 큰 보상을 받는다.
Return
•
에이전트는 누적 보상을 최대화하는 방향으로 학습하며, 누적 보상(Cumulative reward, )을 return, 라고 한다.
•
주로 할인율(dicount factor), 와 함께 쓰인다. (먼 미래의 보상일 수록 덜 중요한 보상이 되도록 한다는 의미적인 이유와, 수열의 합이 수렴하도록 한다는 수학적인 이유 때문에 할인율을 사용한다.)
State
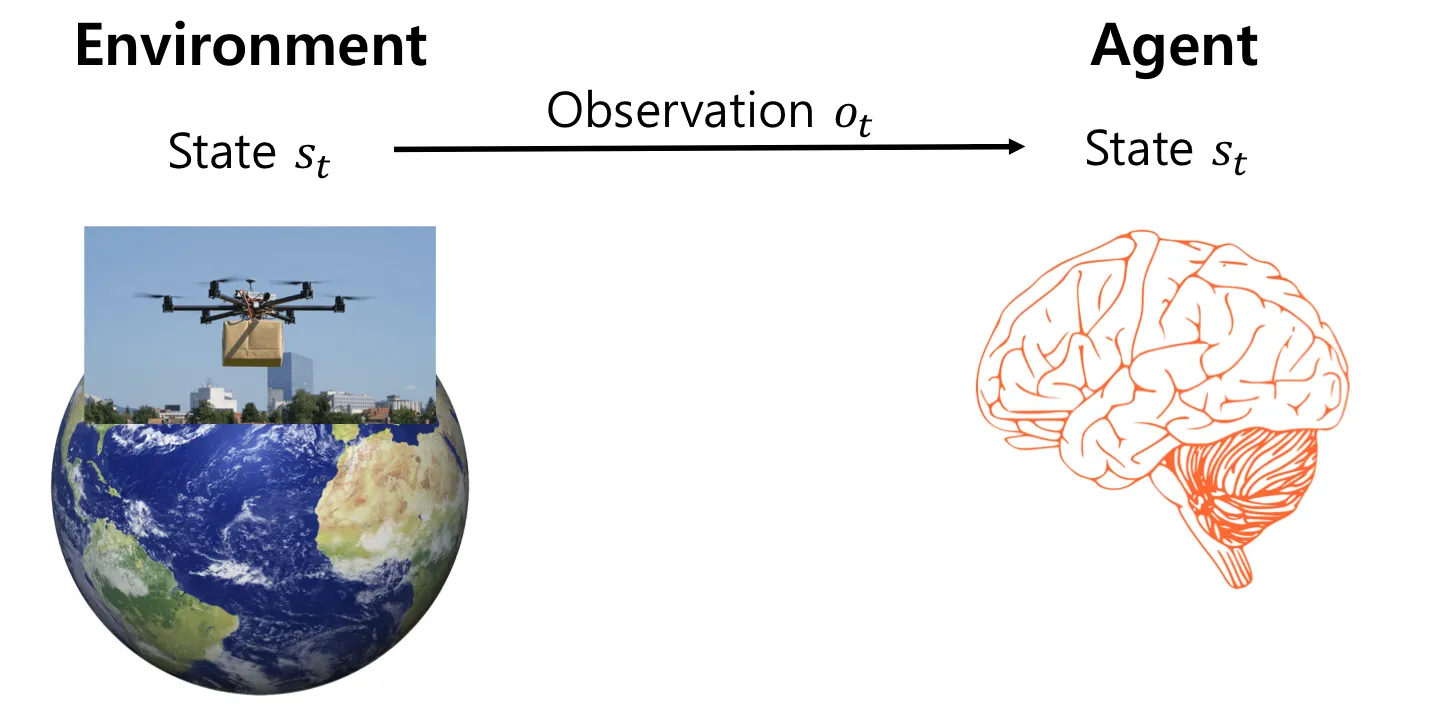
•
특정 시점에서 에이전트가 환경을 관측했을 때 얻게되는 정보를 의미하며, 이 상태 정보를 통해 에이전트는 어떤 행동을 할지 결정하게 된다.
•
Fully observable: environmental state == observation == agent state
◦
에이전트가 환경과 관련된, 혹은 action에 의해서 영향을 받는 모든 변수들을 관측할 수 있음을 의미한다. 체스 게임을 하는 에이전트의 경우 각각의 말이 움직이는 모든 정보를 인지할 수 있기에 Fully observable 하다.
◦
반대로 Partially observable은 환경을 일부만 관측할 수 있음을 의미한다. 포커 게임을 하는 에이전트의 경우 상대방의 패를 볼 수 없기 때문에 안보이는 패에 대한 state는 에이전트가 인지하거나 추론할 수 없고, 따라서 Partially observable하다.
•
History: the full sequence of observations, actions, rewards.
◦
현재 상태()를 정의하려면 과거의 모든 관측, 행동, 보상 정보()를 알아야 한다. → 이렇게 문제가 정의된다면 강화학습으로 문제를 푸는 건 불가능… 가 ‘마르코프 하다’라고 할 수 있으면 문제를 단순화할 수 있다. 마르코프의 의미는 바로 아래에서 다룸!
Markov decision process (MDPs)
•
{} 가 다음을 만족하면 마르코프 결정 과정(Markov decision process)이다.
→ 의 정보량이나 의 정보량이나 같다는 의미이다.
→ 즉 과거의 모든 정보를 알 필요 없이 현재의 상태만으로도 다음 상태를 결정할 수 있게 됨을 의미한다.
→ 가 Markov이면 과거의 모든 히스토리()를 알지 않아도 현재 상태만으로 다음 상태()를 결정할 수 있다.
EX1) 체스 게임의 경우 위에서 바라 본 사진 한장만 있다면 다음에 어떻게 말을 움직일지 결정할 수 있다. → 마르코프o
EX2) 주행중인 자동차에서 전방 사진 한장만 가지고는 다음에 휠을 꺾을지, 가속할지 말지를 결정할 수 없다. 사진 한장만으로는 전진 중인지, 후진 중인지 조차 알 수 없기 때문이다. → 마르코프x
EX3) 주행중인 자동차에서 과거부터 초단위로 3장의 사진을 현재 상태 로 정의한다면 전진 중인지 후진 중인지 알 수 있다. → 마르코프o
Policy
주어진 상황에서 각 행동을 할 확률, 혹은 주어진 상황에서 에이전트가 어떤 행동을 할지를 의미한다.
강화학습에서 학습의 대상이 되는 부분으로서 return, 을 최대화 하는 방향으로 업데이트 된다.
•
정책 함수
두가지 종류가 있다.
◦
Stochastic policy
: 상태 s에서 행동 a를 취할 확률을 의미한다.
◦
Deterministic policy
: 상태 s에서 어떤 행동을 할지를 의미한다. ex) 스칼라 값 0,1,2 …
Value
return, 의 기댓값을 value라고 한다.
•
State value: 상태 가 얼마나 좋은지…
•
Action value : 상태 에서 행동 를 하는 것이 얼마나 좋은지…
상태 가치 함수와 행동 가치 함수는 return의 기댓값을 구한다는 점에서 거의 비슷하다고 볼 수 있고, 에서 기댓값을 구하느냐, 에서 행동 를 했을 때 기댓값을 구하냐의 차이가 있을 뿐이다(행동을 하기전의 리턴 기댓값 vs 행동을 하고 그에 대한 보상을 얻고 난 후 리턴 기댓값…). 는 로, 는 로 표현될 수 있다.
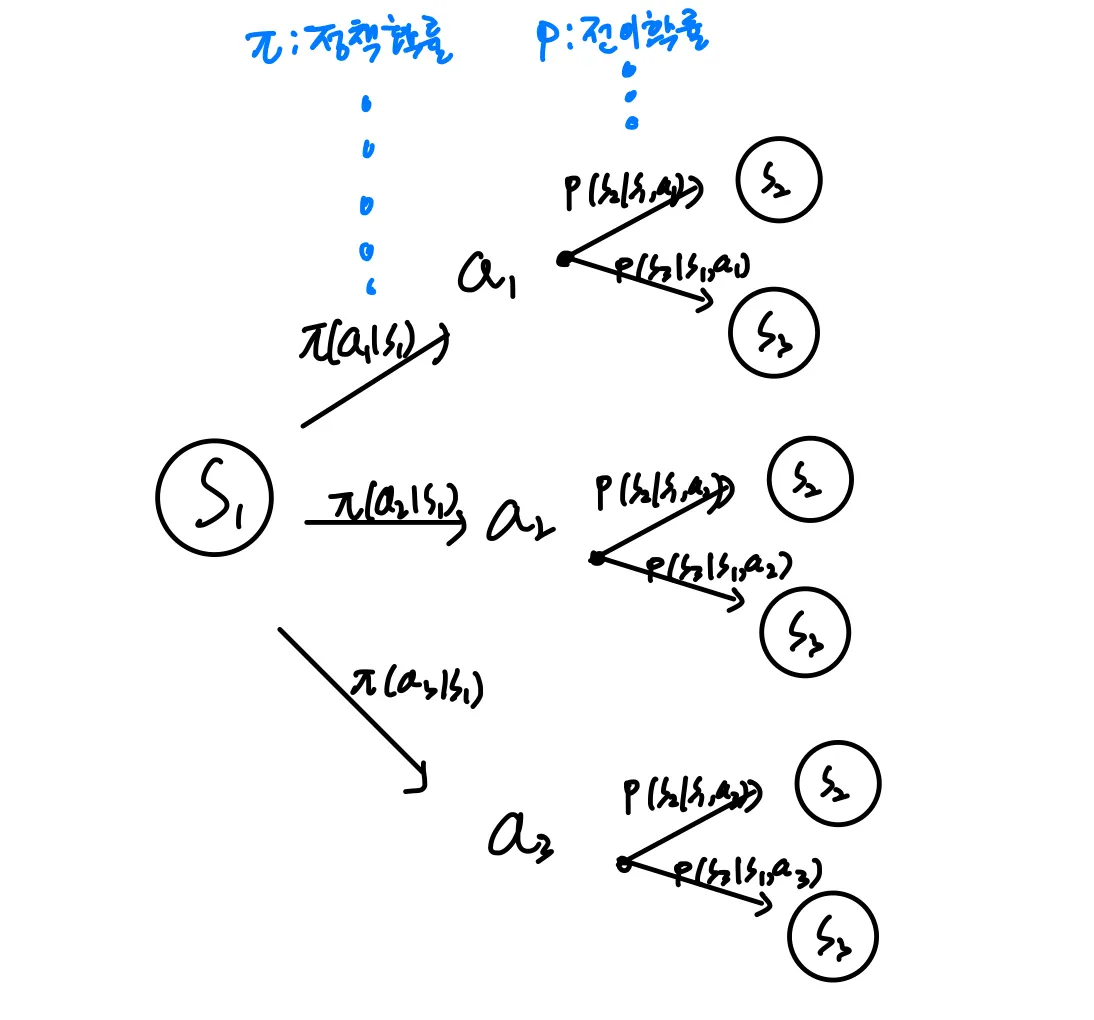
에서 로 전이할 때 정책확률와 전이확률 라는 두개의 확률이 적용됨을 짚고 넘어가자. 다음주 벨만 방정식을 공부할 때 더 잘 이해할 수 있을 것이다.
Prediction and Control
강화학습은 크게 두 단계로 구분된다.
•
Prediciton
: 가 주어졌을 때, 각 상태의 밸류를 평가하는 문제.
•
Control
: 최적정책 를 찾는 문제.
Prediction과 Control은 서로 번갈아 가며 진행되며, Prediction을 여러번하고 Control하거나 한번씩만 번갈아 하거나 등 그 양상은 방법론에 따라 다를 수 있다.
Categories of RL
어떻게 학습하는지에 따라
•
Value-based learning (일반적인 강화학습의 경우…)
: Learns value while policy is implicitly updated
•
Policy-based learning
: Learns policy don’t care how exact return would be (no value)
•
Actor-critic
: Actor learns policy, Critic criticize based on the value it learned
모델여부에 따라
•
Model-based
: 직접 경험하지 않아도 환경에 대한 모든 정보를 이미 알고있는 경우의 강화학습 접근법이다. 즉 s에서 a를 할 때 얻는 보상 과 s에서 a를 할 때 s’으로 전이할 확률 까지 전부 알고 있다면 굳이 에이전트가 직접 경험하면서 정보를 모을 필요 없이 Value 함수를 구할 수 있다. 경험하지 않고도 최적 솔루션을 찾을 수 있기에 이라고도 불린다.
•
Model-free
: 환경에 대한 정보를 모르는 좀 더 일반적인 경우에서의 강화학습 접근법이다. 에이전트가 주어진 혹은 임의의 정책을 이용해 직접 경험해 보면서 Value 함수를 업데이트 하고 정책을 개선해 나가게 된다.