
1.
Transformer 구현
참조논문: Attention Is All You Need
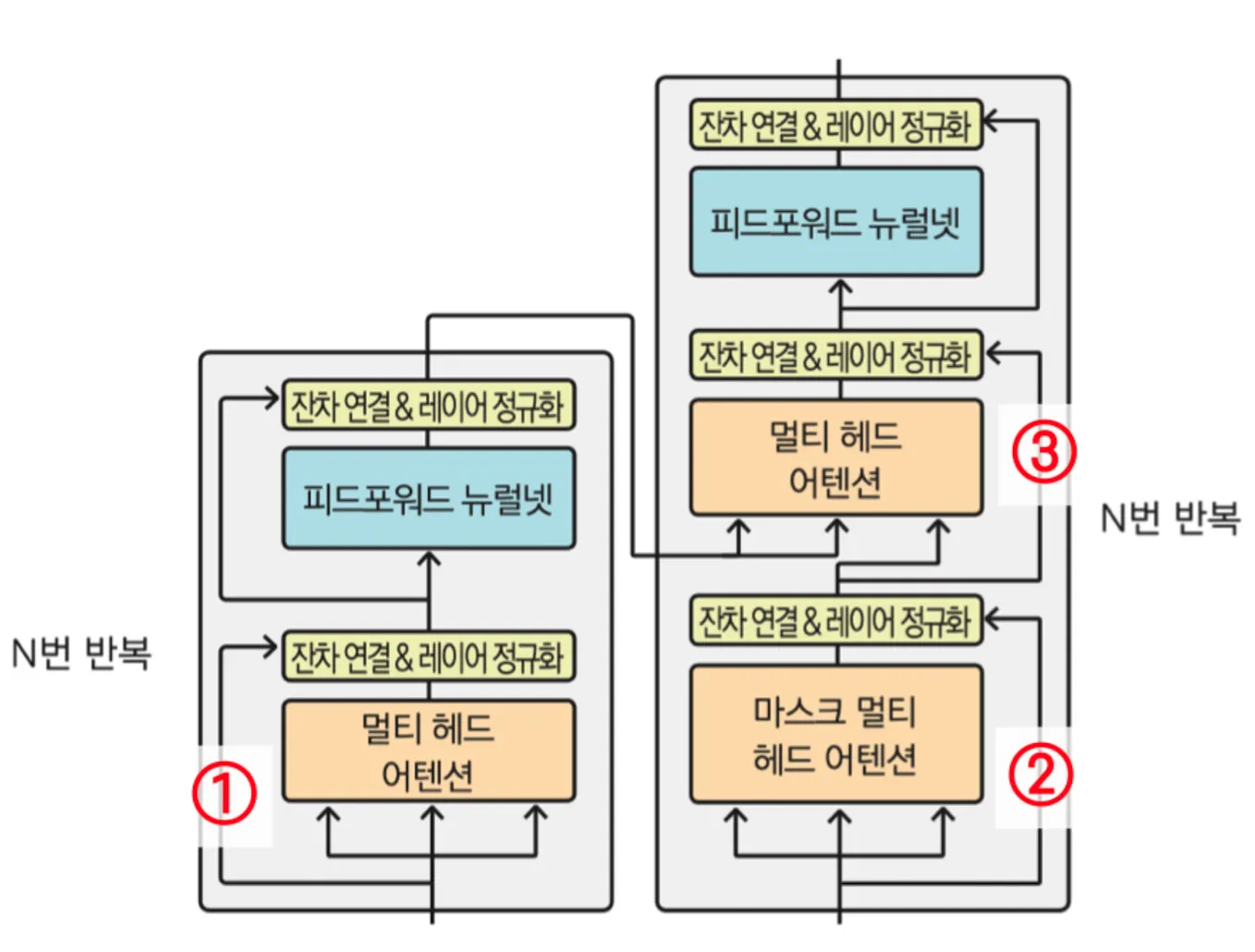
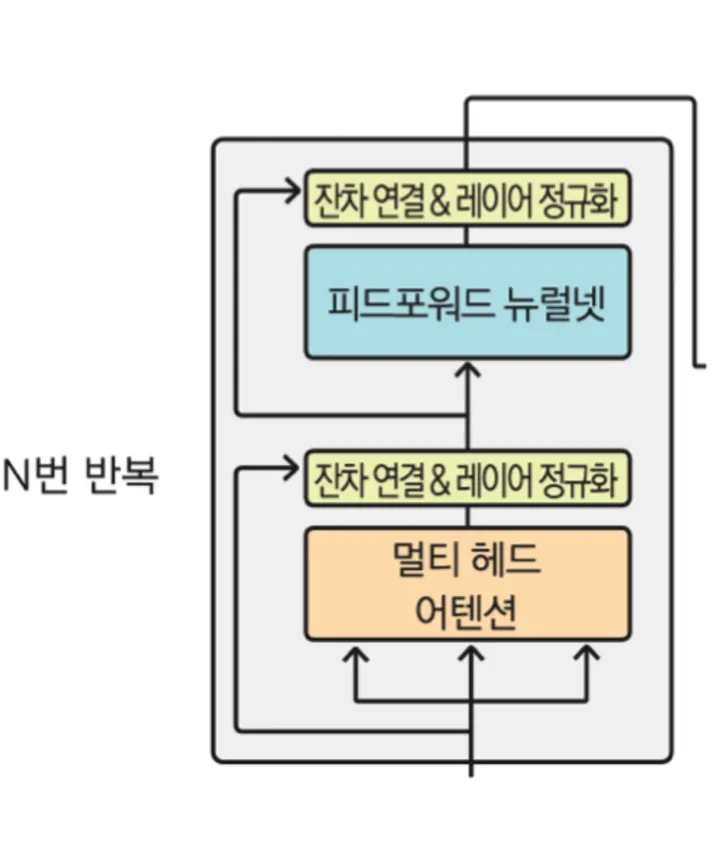
전체적인 틀은 이러하다!

•
코드와 함께 살펴봅시다
시작~

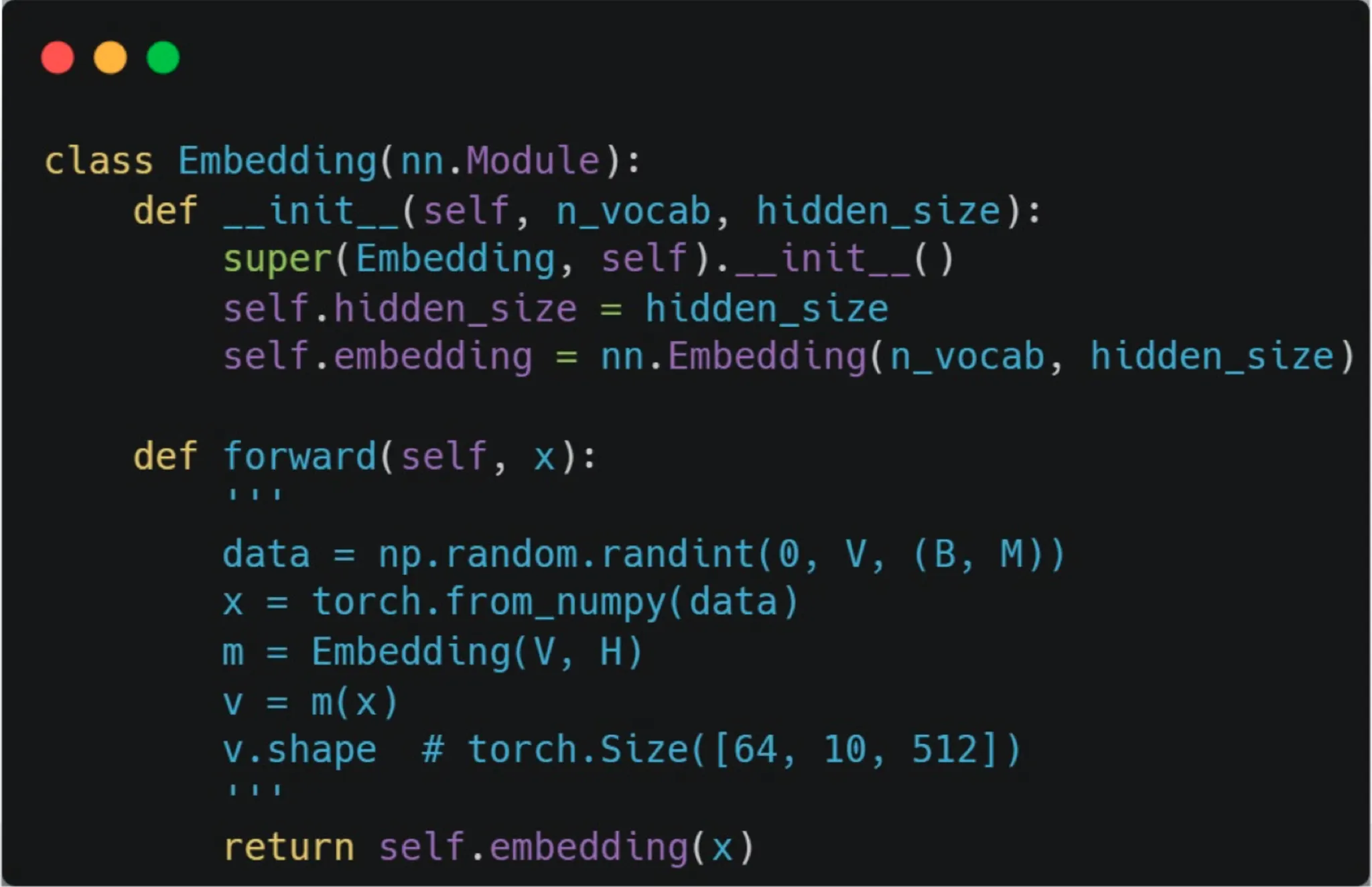
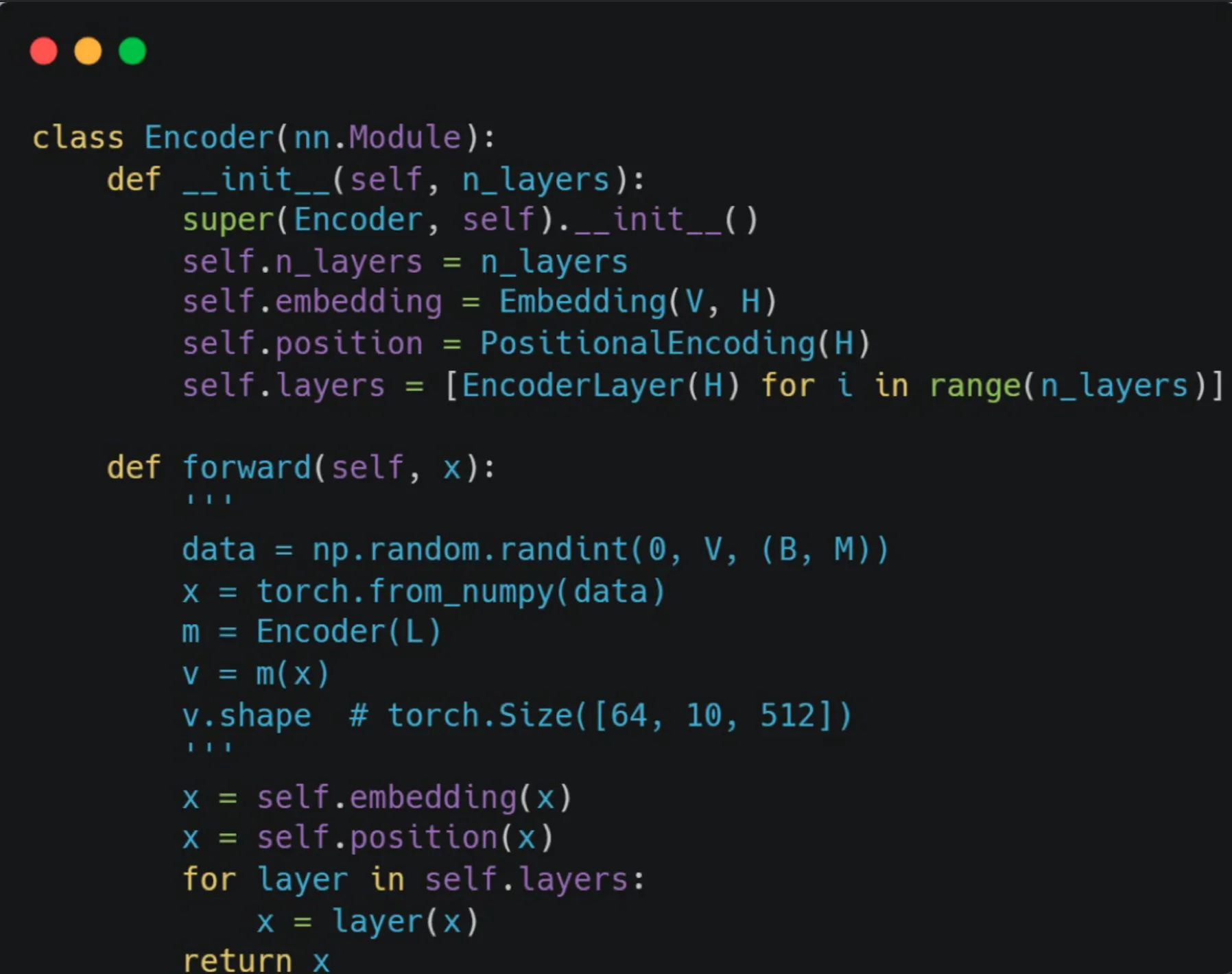
(Embedding)
(Positional encoding)
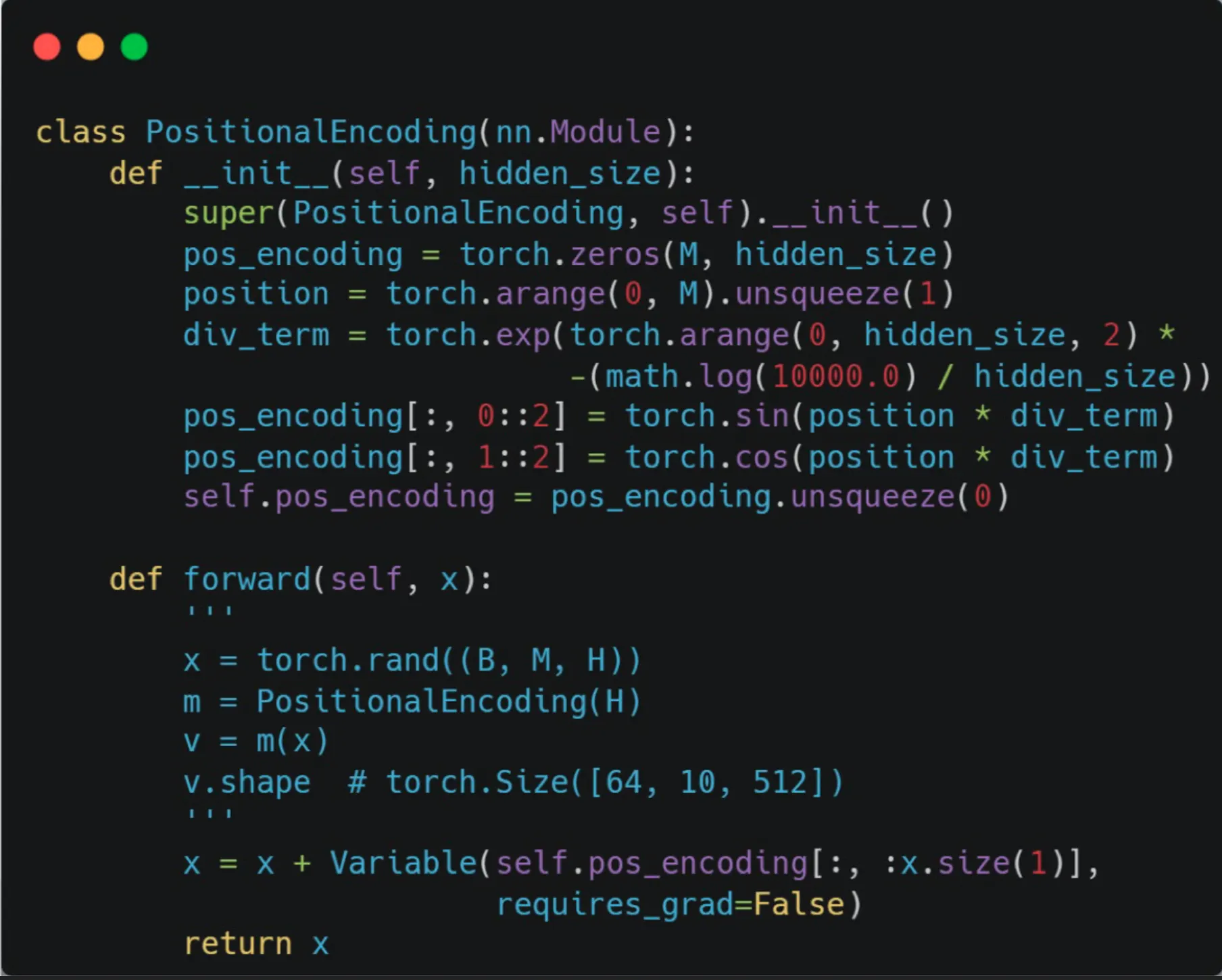
→RNN의 경우 시간축에 따라 넣어줬지만 Transformer는 시간축에 대한 정보가 없다.
이 때문에 Postional encoding vector 를 추가로 구해서 임베딩 벡터에 더해준다.
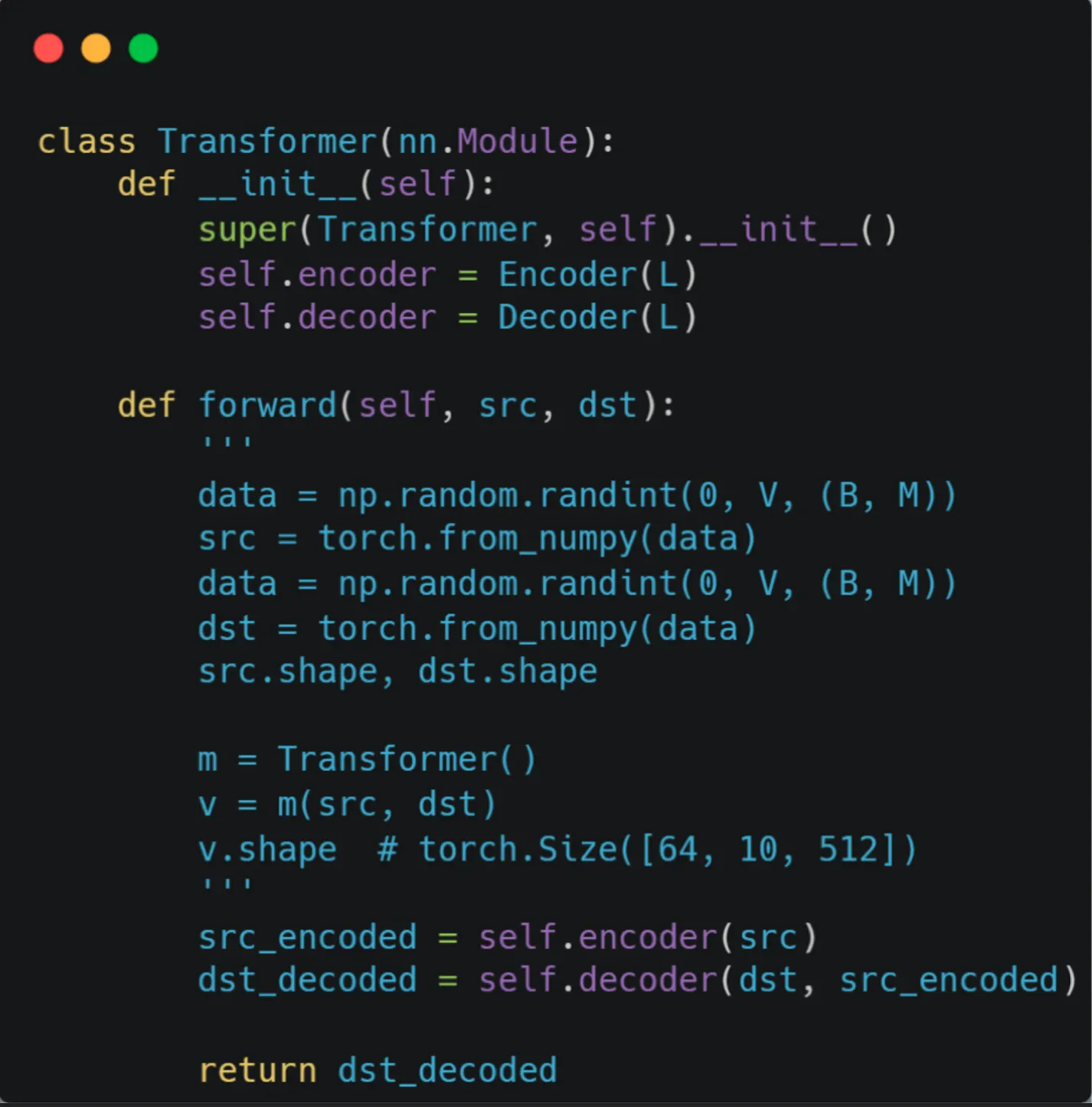
Transformer Class 생성
1번: <Encoder>
•
Encoder의 self attention
→ Attention Score 계산
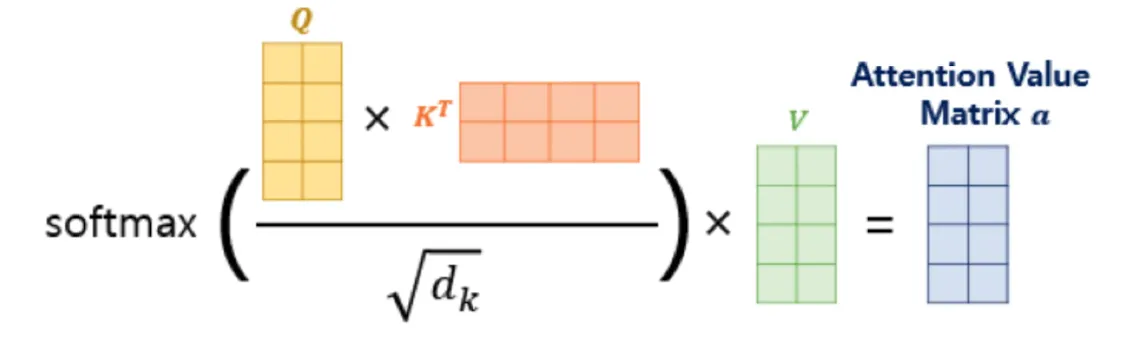

이때 필요한 수식!!
여기서 point :
Q와 K의 유사도를 통해 계산한 값이 Attention score
Q(query) 다른 단어들과의 유사도를 계산하기 위해 사용.
K(key)는 다른 단어들과 비교할때 사용하는 매트릭스.
Q를 다른 단어와 비교 할때 다른 단어의 Q가 아닌 K와 비교한다.
왜냐? 각 단어마다 기준이 다르니까!
이렇게 계산된 값이 V(value)과 연결되어 Attention Value Matrix로 저장된다.
→ 이렇게 Q,K,V를 구분되게 해놓으면 더욱더 복잡하게 구성 가능하다
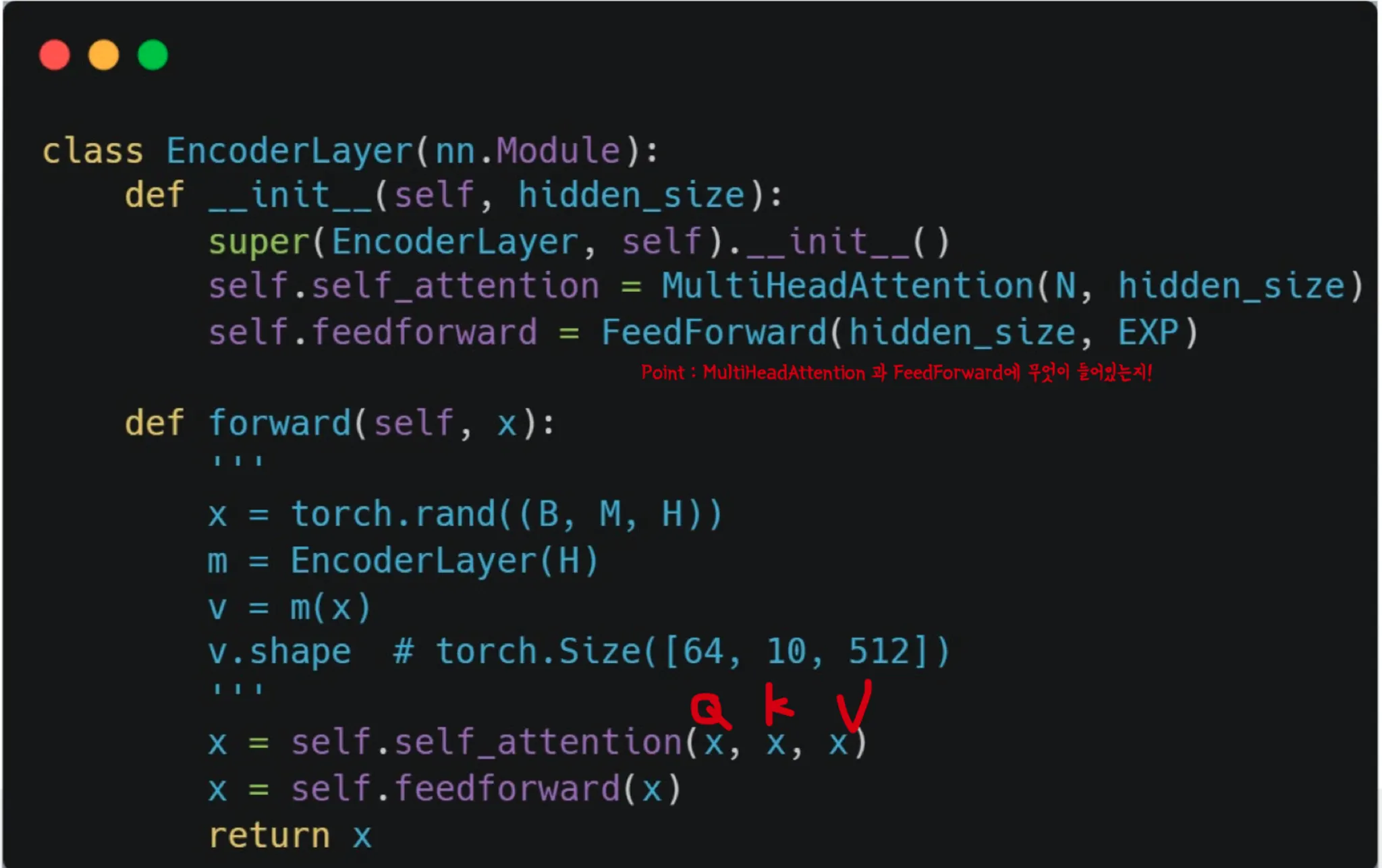
Feed Foward Neural Network(FFNN)
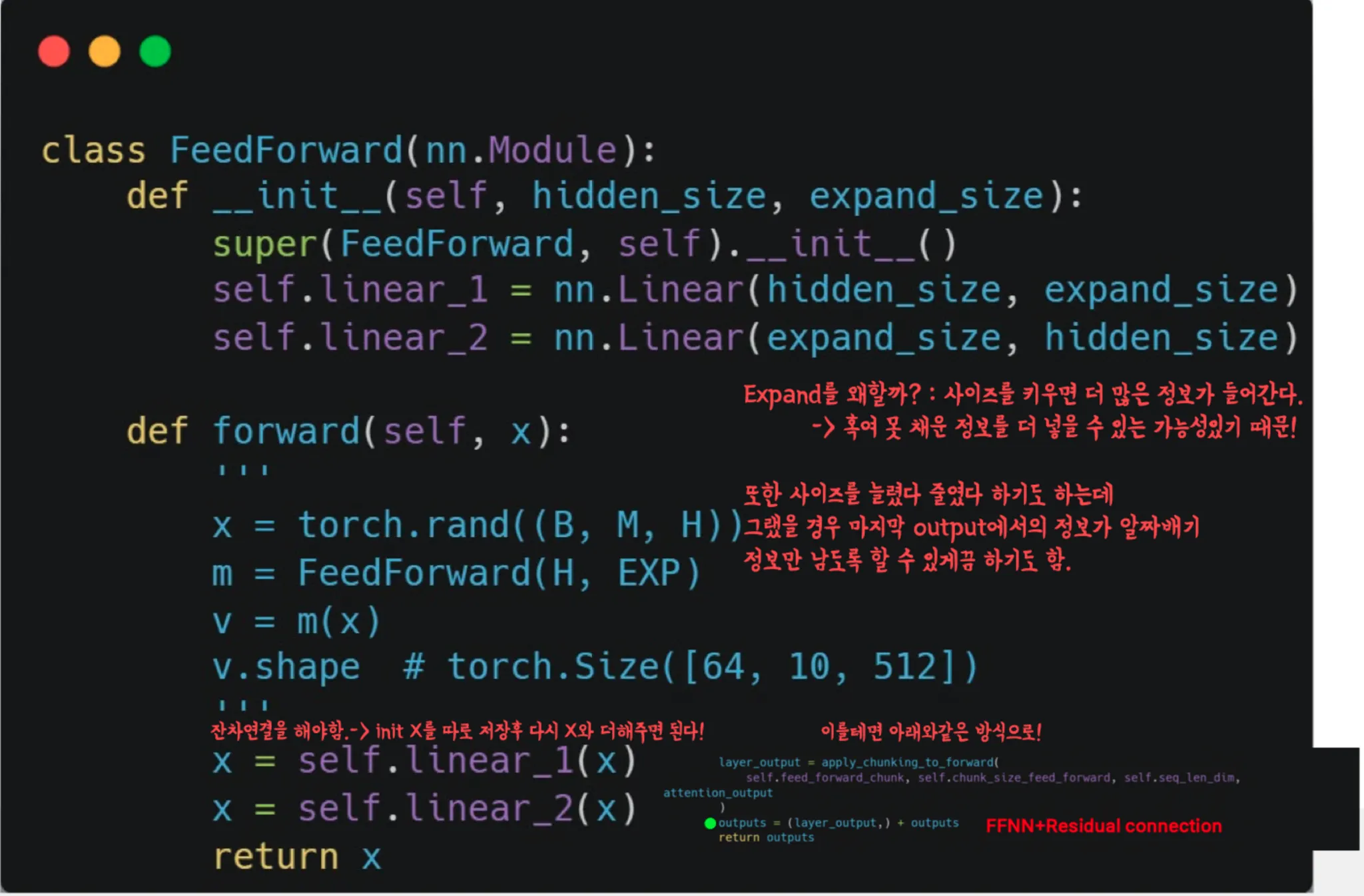
•
Multi head attention
Multi head 는 CNN의 서로 다른 필터들과 채널들이 존재해서 다른 정보들을 추출하도록 하는 것과 유사하다.
Multi head 의 과정—→
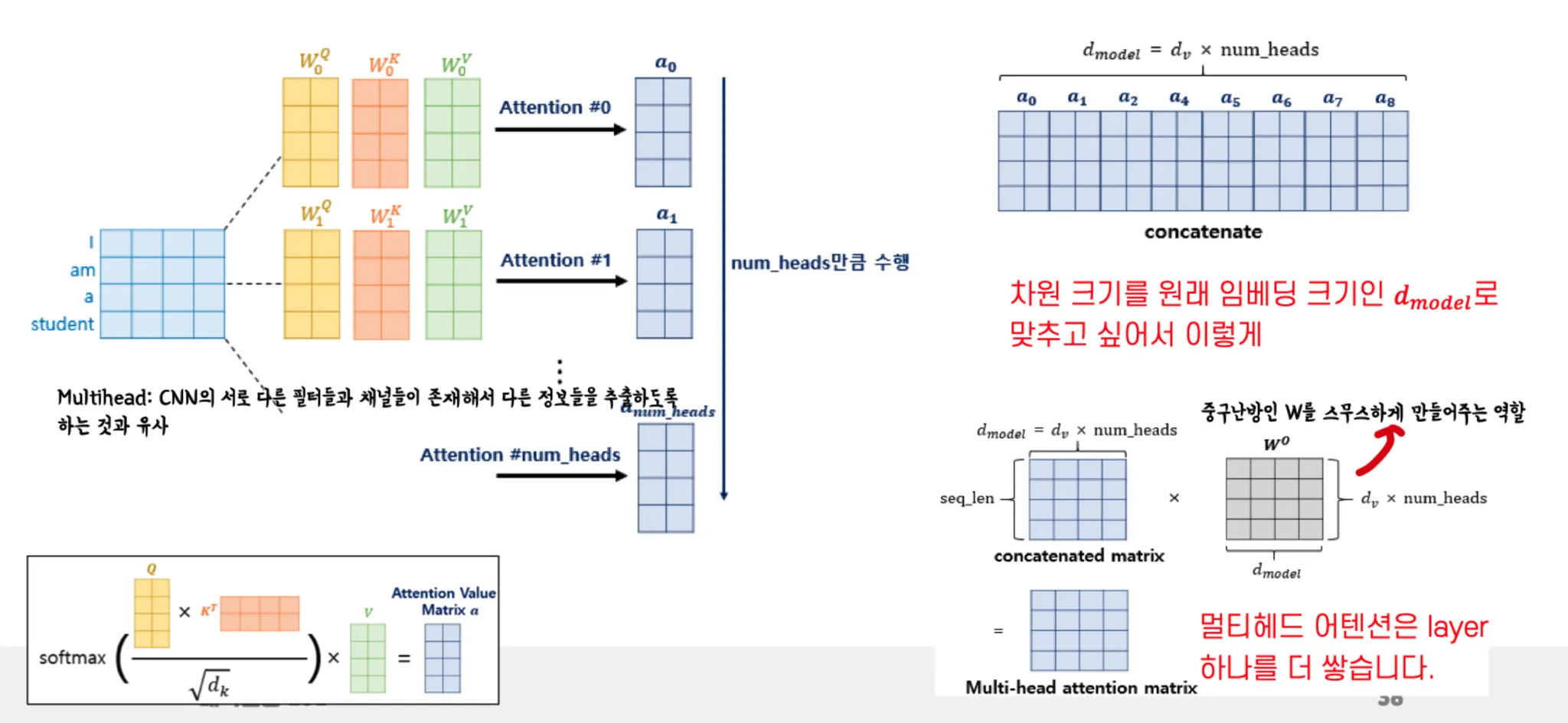
마지막에 layer 하나를 더 추가하는 이유는 필기해놓은것처럼 중구난방인 W를 스무스하게 만들어주기 위해서.
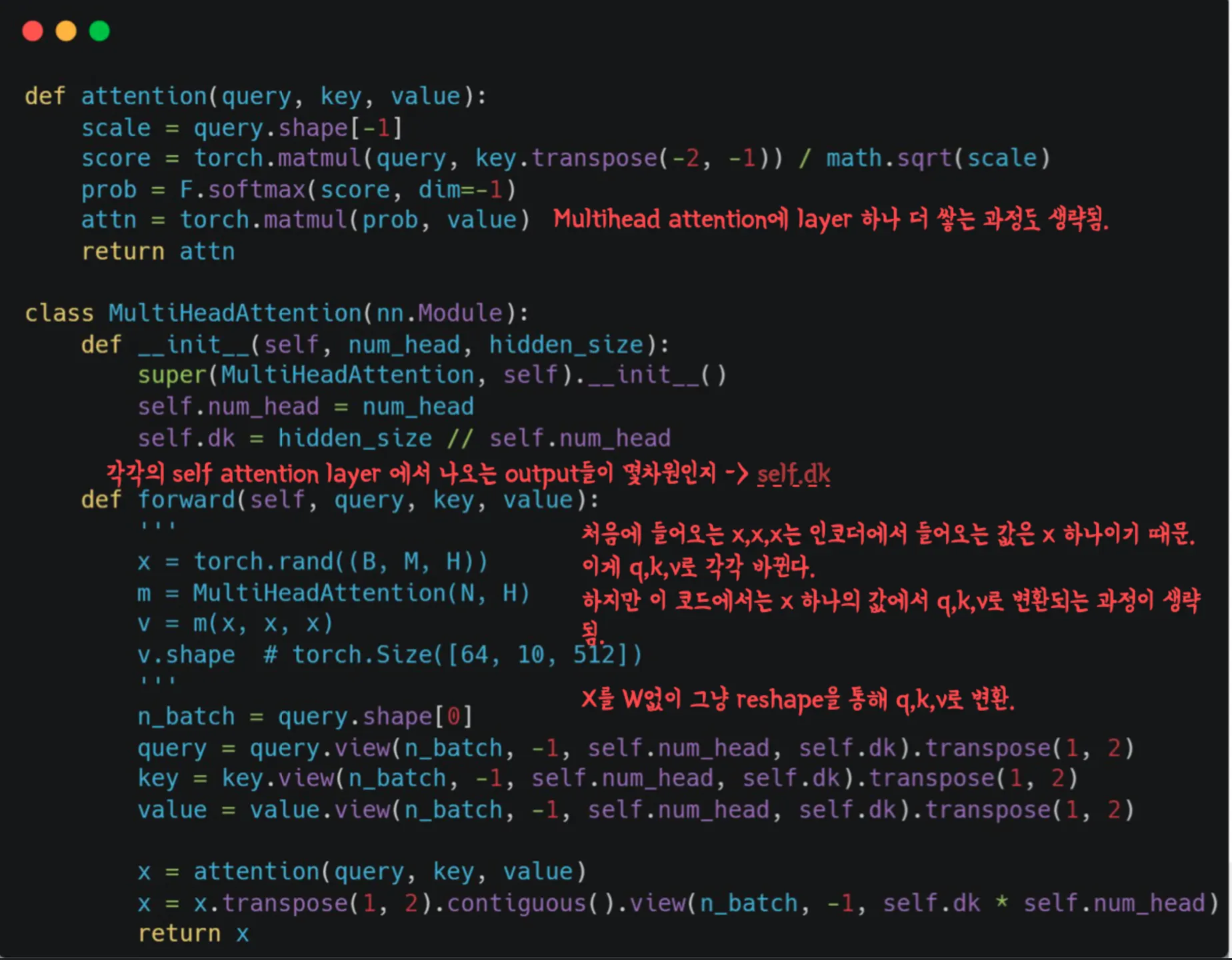
-누락된 몇몇 요소들을 포함한 전체적인 Encoder 코드-
모두 가져오면 너무 길기 때문에..
누락된 Masking, 잔차연결 과 Multihead 에서 layer 하나 더 쌓는 과정 정도만…
→ MASK
def makeMask(tensor, option: str)-> torch.Tensor:
if option== 'padding':
tmp= torch.full_like(tensor, fill_value=PAD_IDX).to(device)
# tmp : (bs,seq_len)
mask= (tensor!= tmp).float()
# mask : (bs, seq_len)
mask= rearrange(mask, 'bs seq_len -> bs 1 1 seq_len ')
elif option== 'lookahead':
mask= makeMask(tensor, 'padding')
padding_mask= repeat(
padding_mask, 'bs 1 1 k_len -> bs 1 new k_len',
new=padding_mask.shape[3])
# padding_mask : (bs, 1, seq_len, seq_len)
mask= torch.ones_like(padding_mask)
mask= torch.tril(mask)
mask= mask* padding_mask
# ic(mask.shape)
return mask
Python
복사
→ 잔차 연결

→Multi head layer 하나 추가
#(초반부)
class Multiheadattention(nn.Module):
def __init__(self, hidden_dim: int, num_head: int):
super().__init__()
self.scale= torch.sqrt(torch.FloatTensor()).to(device)
self.fcQ= nn.Linear(hidden_dim, hidden_dim)
self.fcK= nn.Linear(hidden_dim, hidden_dim)
self.fcV= nn.Linear(hidden_dim, hidden_dim)
self.fcOut= nn.Linear(hidden_dim, hidden_dim)
self.dropout= nn.Dropout(0.1)
# 이어서 forward 부분 나오고
...
...
...
# 마지막 layer 하나 더 쌓아주는 부분
result = self.fcOut(result)
Python
복사
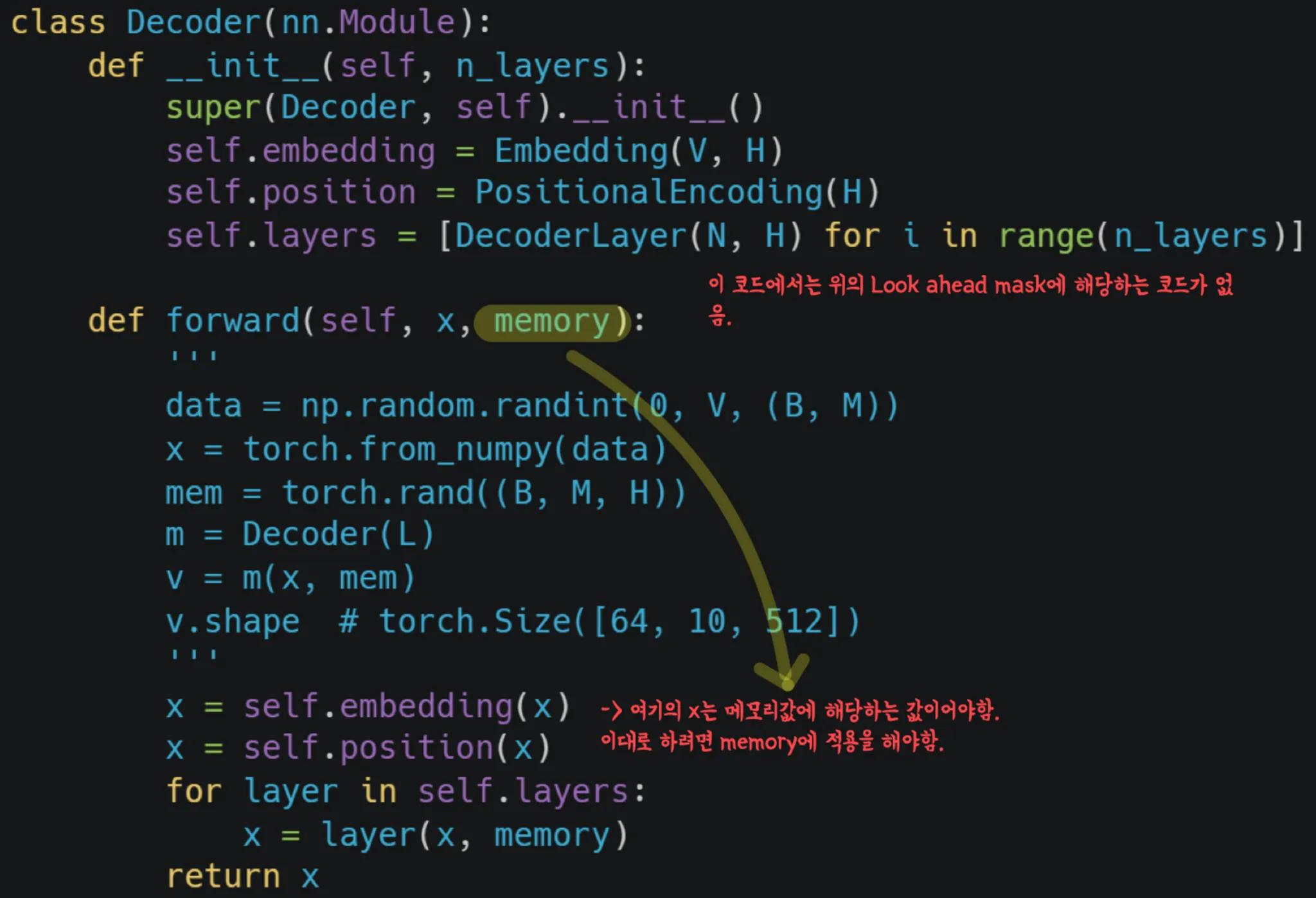
2번: <Decoder>
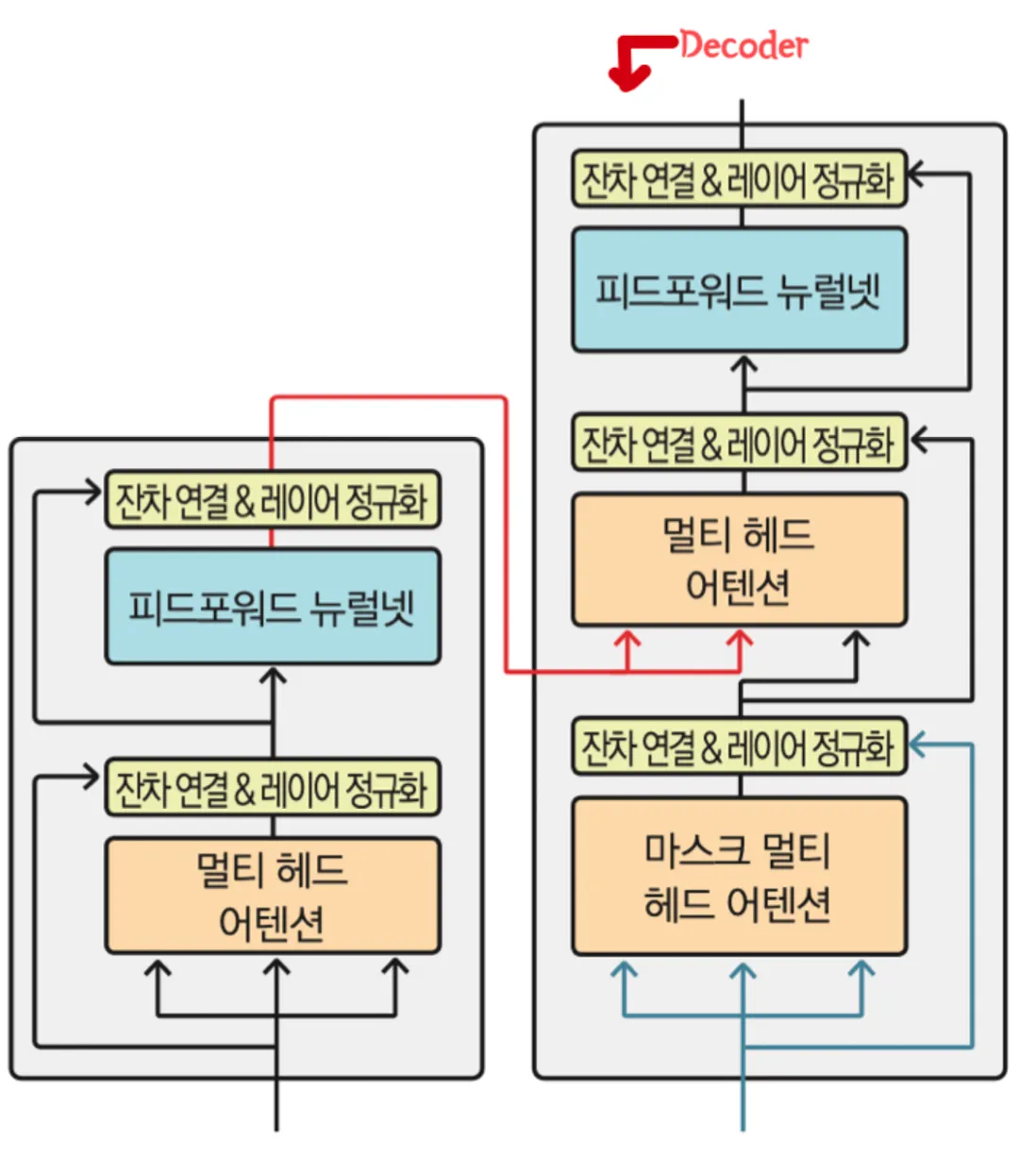
Decoder 에서는 Q,K,V의 source들이 다르다.
(하지만 Encoder/Decoder 1층에서는 같다)
Decoder 2층에서
Q → Decoder 에서 온 Mask Multi head attention 을 통해 올라온 attention 행렬
K,V → Encoder에서 나온 attention 행렬
<왜 이렇게 구성되어있나?>
•
Decoder에서 나온 값과 Encoder에서 나온 값을 비교해 Encoder에서 나온 값 어디에 더 집중을 할 건지 결정하기 위함임.
•
Deocder에서 온 정보를 해독하기 위해서는 Encoder에서 나온 attention행렬 “어느 부분”에 집중해야하는지를 연산하기 위함.
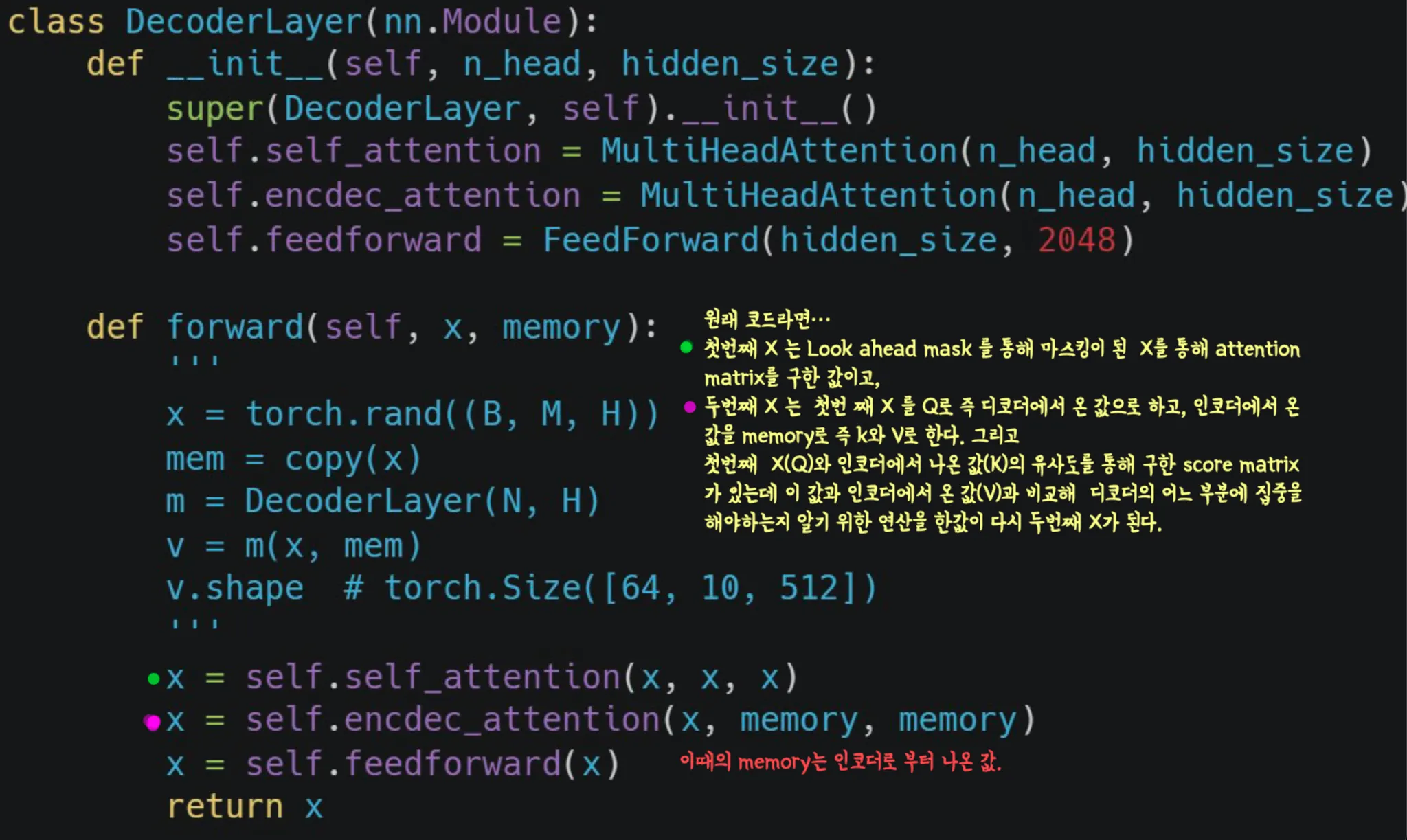
Encoder 와 마찬가지로 누락된 부분을 깃허브 코드를 참조하여 확인해봅시다.
# 앞서 나온 FFNN과는 조금 다른 이름으로 적혀있지만 누락된 정규화와 마스킹이 포함되어있습니다. 또한 Multi head 에 layer 하나를 더 쌓는 것도 포함되어있는 코드입니다.
class DecoderLayer(nn.Module):
def __init__(self, d_model, ffn_hidden, n_head, drop_prob):
super(DecoderLayer, self).__init__()
self.self_attention = MultiHeadAttention(d_model=d_model, n_head=n_head)
self.norm1 = LayerNorm(d_model=d_model)
self.dropout1 = nn.Dropout(p=drop_prob)
self.enc_dec_attention = MultiHeadAttention(d_model=d_model, n_head=n_head)
self.norm2 = LayerNorm(d_model=d_model)
self.dropout2 = nn.Dropout(p=drop_prob)
self.ffn = PositionwiseFeedForward(d_model=d_model, hidden=ffn_hidden, drop_prob=drop_prob)
self.norm3 = LayerNorm(d_model=d_model)
self.dropout3 = nn.Dropout(p=drop_prob)
def forward(self, dec, enc, trg_mask, src_mask):
# 1. compute self attention
_x = dec
x = self.self_attention(q=dec, k=dec, v=dec, mask=trg_mask)
# 2. add and norm
x = self.dropout1(x)
x = self.norm1(x + _x)
if enc is not None:
# 3. compute encoder - decoder attention
_x = x
x = self.enc_dec_attention(q=x, k=enc, v=enc, mask=src_mask)
# 4. add and norm
x = self.dropout2(x)
x = self.norm2(x + _x)
# 5. positionwise feed forward network
_x = x
x = self.ffn(x)
# 6. add and norm
x = self.dropout3(x)
x = self.norm3(x + _x)
return x
Python
복사
2.
BERT 와 variants
•
BERT
Points : Upstream task에서 MLM(Masked Language Model)과 NSP(Next Sentence Prediction)로 학습하고 Downstream task에서 목적에 맞게 Fine tuning한다!
특이점: 1) 앞서 나온 Transformer의 Encoder 부분을 깊게 쌓는다. (12층)
2) Input을 sentence pair를 사용
3) 워드피스 토크나이저를 사용 (문장을 사용하기 때문)
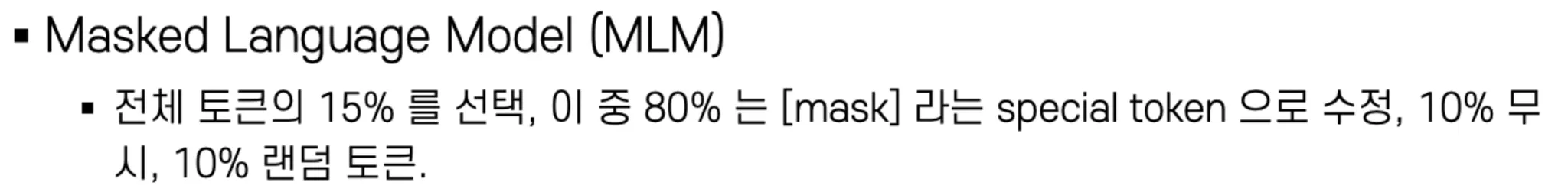

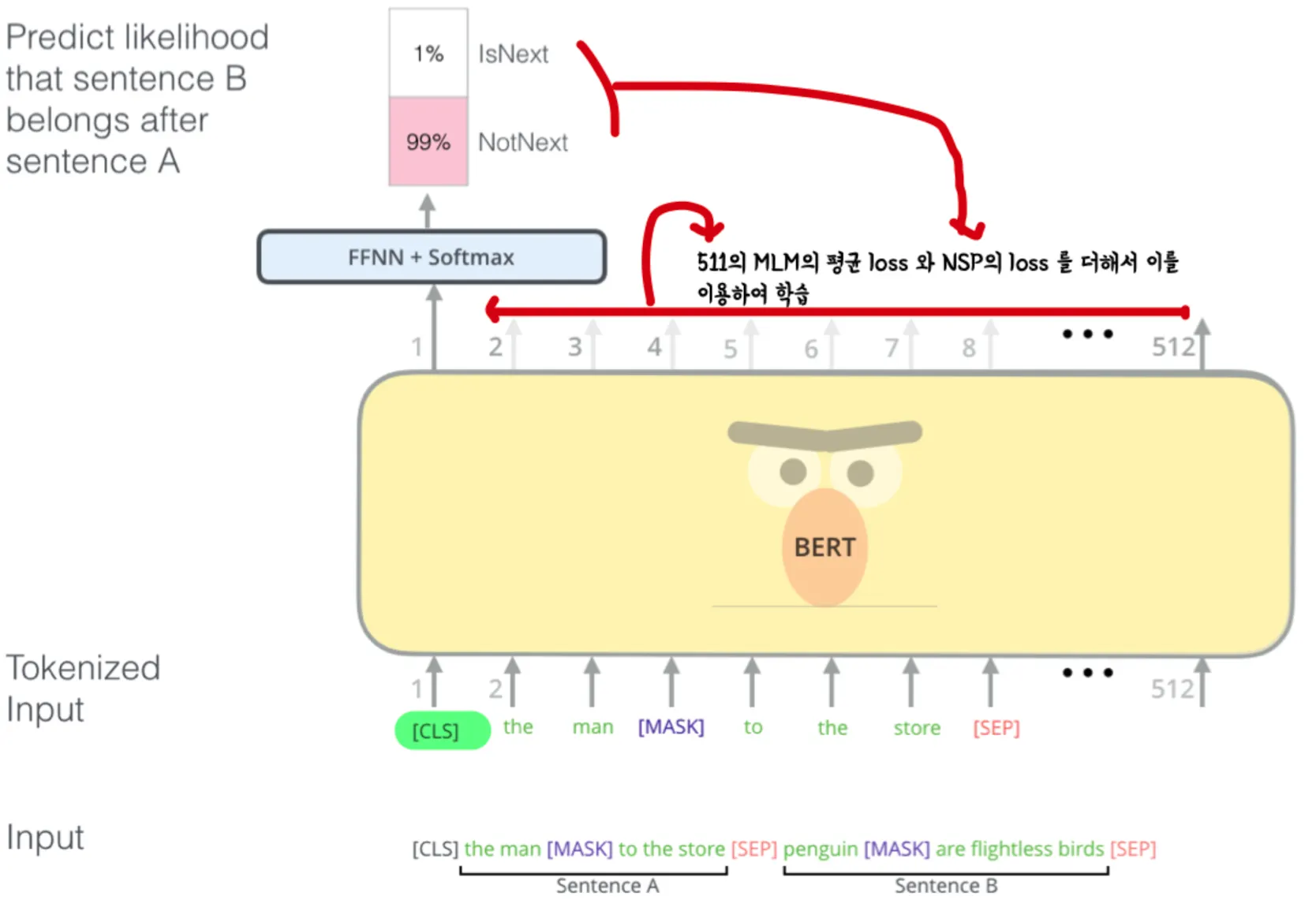
Bert의 Embedding → 문장을 사용하기 때문에 Embedding 이 다른 모델과는 차이가 있다.
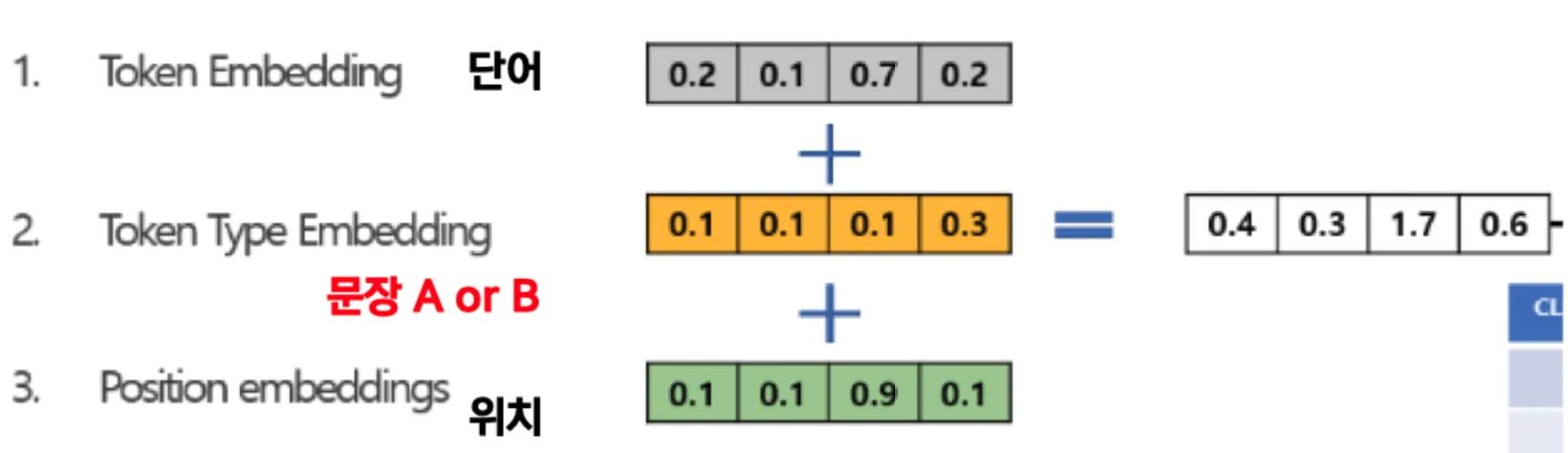
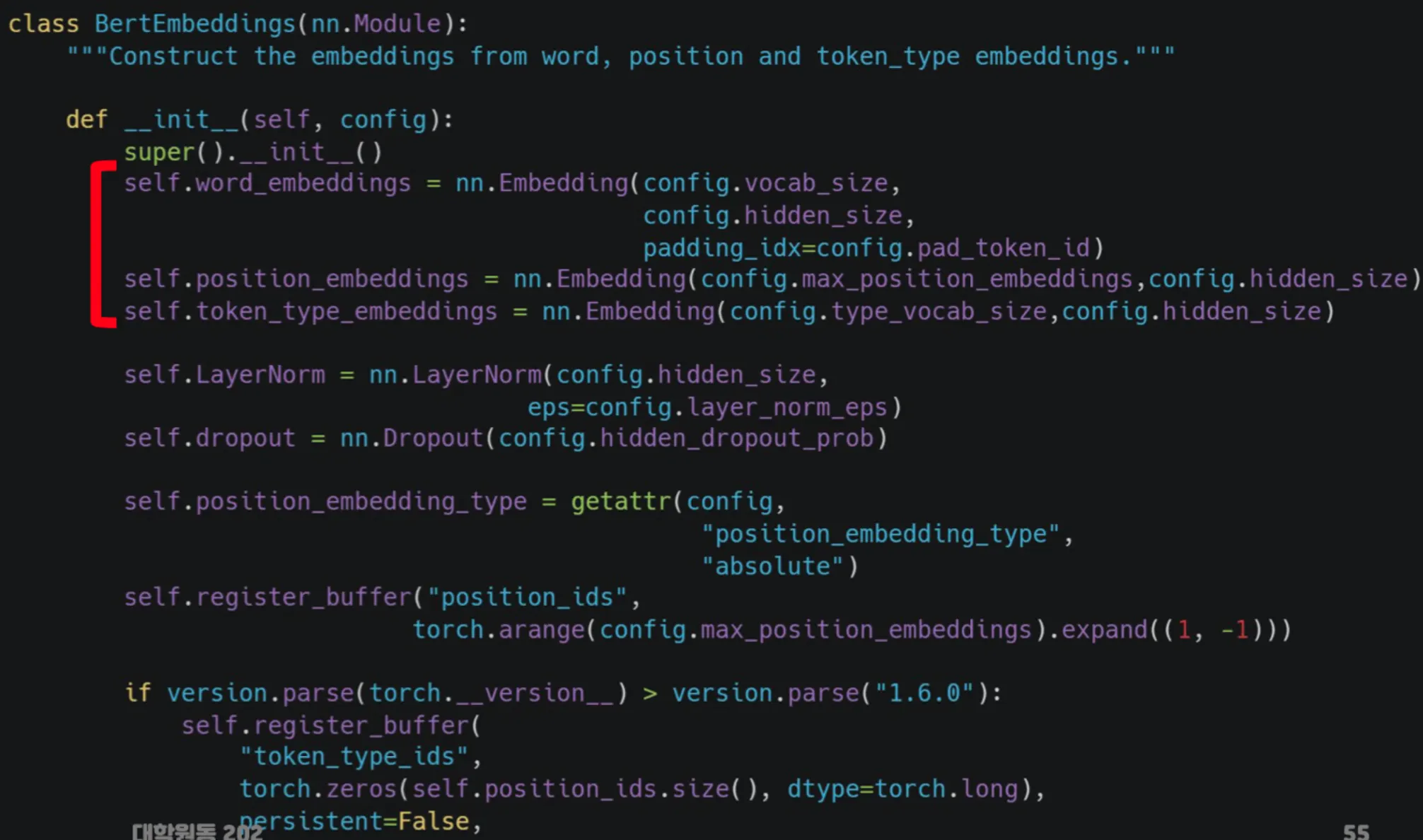
나머지 코드는 transformer를 기반으로 하므로 틀은 차이점에서 언급한 부분을 제외하면 크게 다르지 않다.
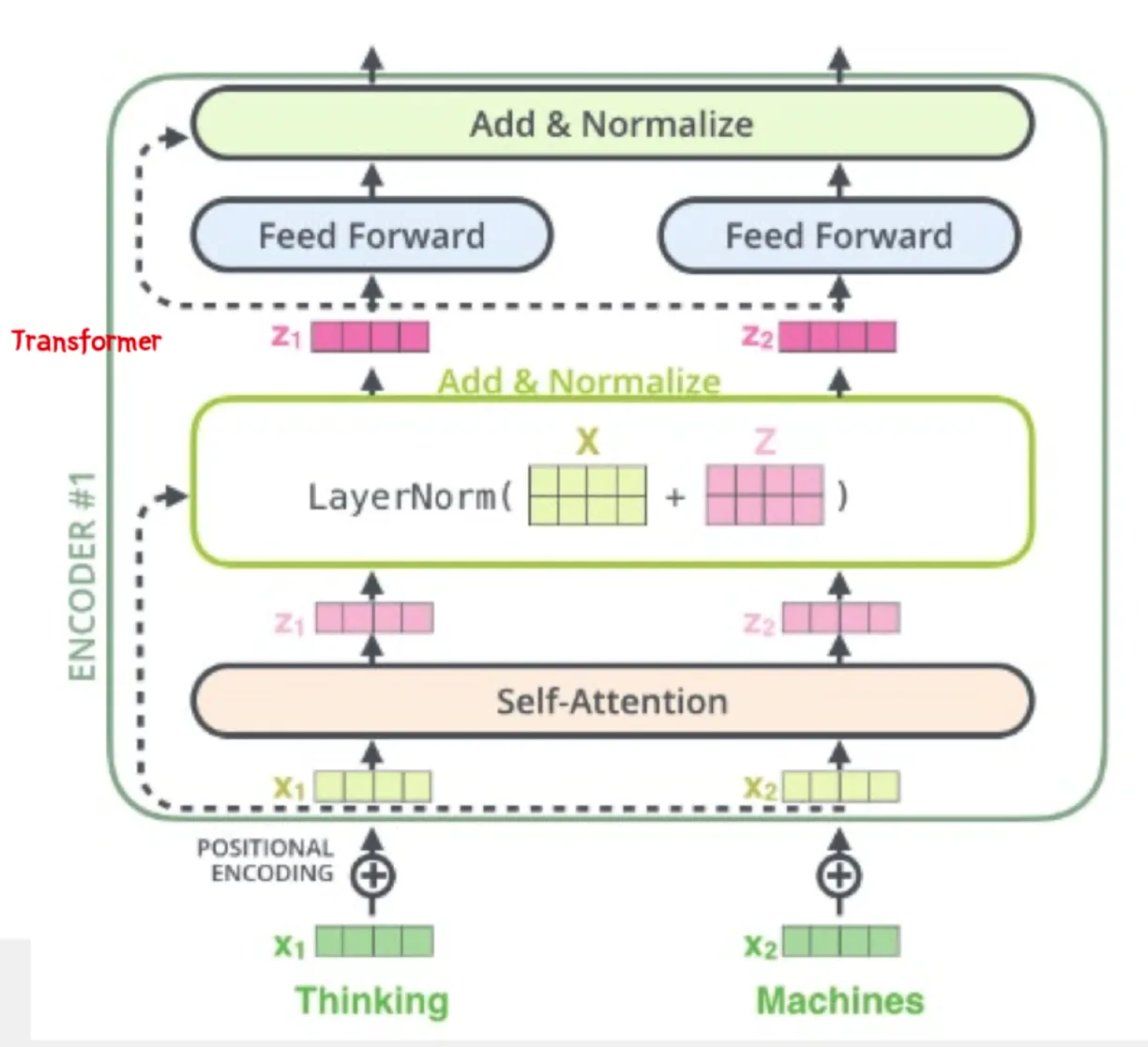
•
GPT
BERT가 Transformer의 Encoder 였다면 GPT는 Decoder를 활용한 모델.
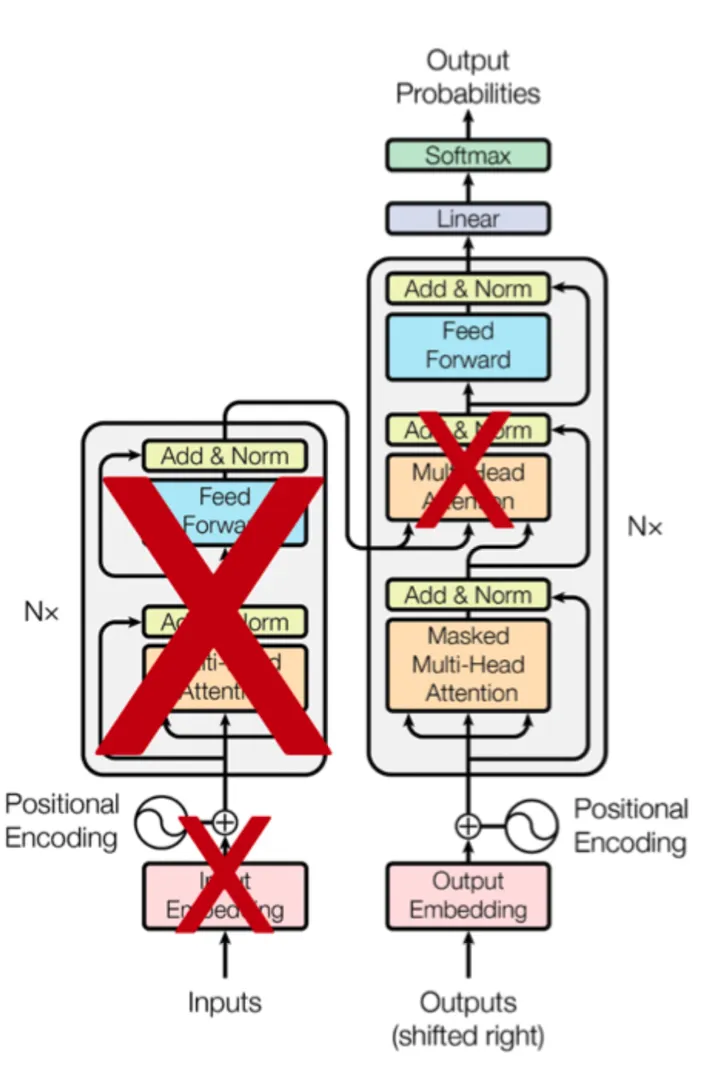
•
RoBERTa
구조적으로 BERT와 완벽히 동일하지만 최적화시킨 모델.

•
ALBERT
임베딩 파라미터 및 모델 크기를 줄이는 방법의 BERT
•
ELECTRA
Upstream task 로 replace task detection(RTD)를 사용하였다는 점에서 BERT류와는 완전히 다른 모델
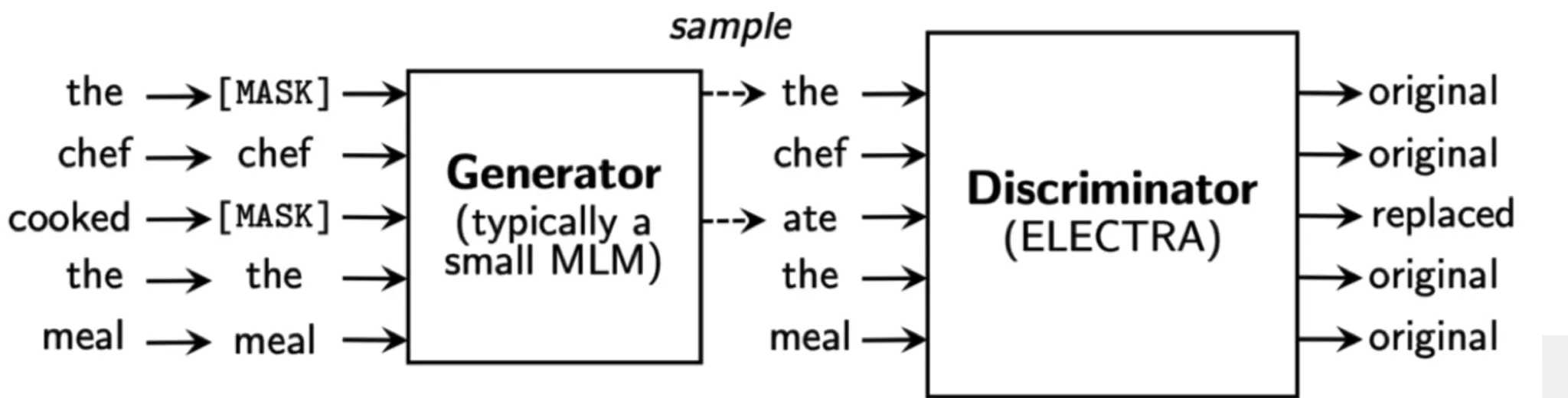
오히려 GAN과 유사함. [mask]를 다른 단어로 바꾸고 이 단어가 원래 있는 단어인지 교체된 단어인지를 확인함.
→ 연산량 대비 더 좋아보인다 정도.
<Citation>
