
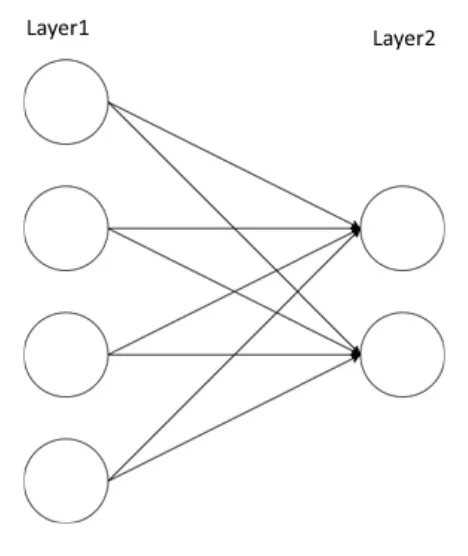
전연결 레이어의 작동 방식
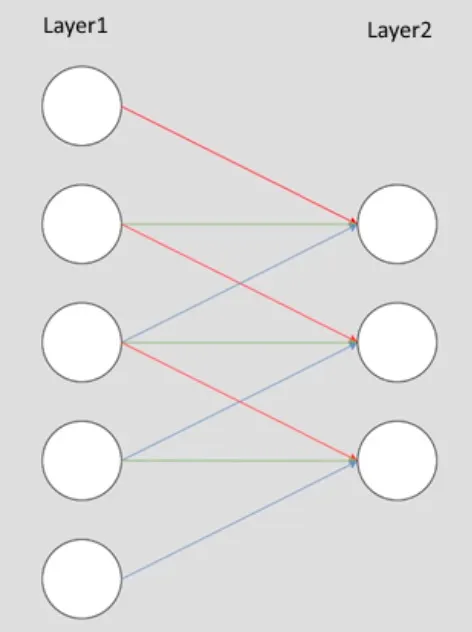
컨볼루션 연산 작동방식
컴퓨터 비전에 선형 레이어 또는 전연결 레이어를 사용할 때 가장 큰 문제점은 모든 공간 정보를 잃어버리고 전연결 레이어가 사용하는 가중치의 복잡성이 너무 크다는 점이다.
풀링
컨볼루션 레이어 다음에 Pooling 레이어를 추가하는 것이 일반적이다.
풀링 레이어는 피처 맵 Feature map의 크기와 컨볼루션 레이어의 출력을 줄이는 역할을 담당한다.
풀링의 기능
1.
처리할 데이터의 크기를 줄인다.
2.
알고리즘이 이미지 위치의 작은 변화에 집중하지 않도록 만드는 것
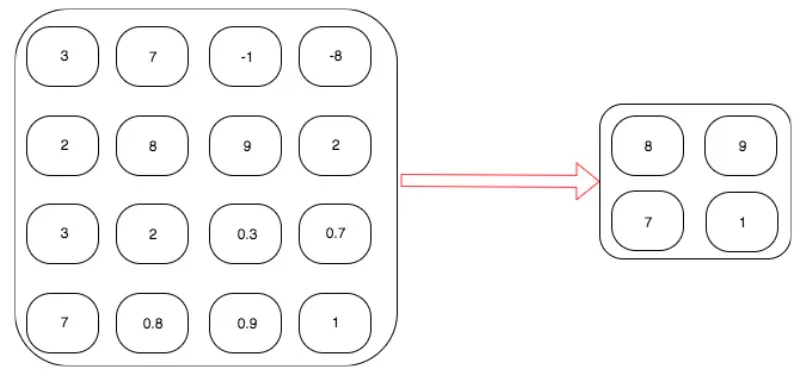
MaxPool2d 동작 방식
출력 1 → Maximum(3,7,2,8) → 8
출력 2 → Maximum(-1,-8,9,2) → 9
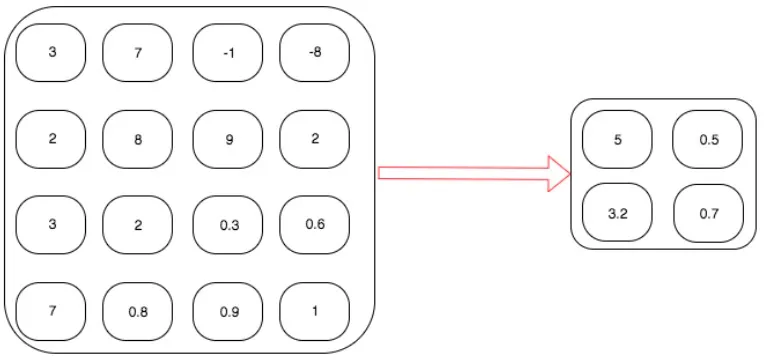
AveragePool2d
출력 1 → Maximum(3,7,2,8) → 5
출력 2 → Maximum(-1,-8,9,2) → 0.5
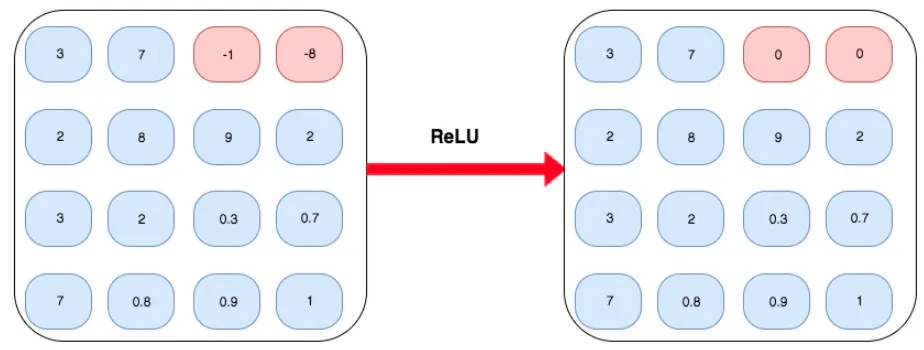
비선형 활성화 레이어 - ReLU
일반적으로 컨볼루션을 수행한 후, 맥스 풀링을 진행한다.
그 후, 비선형 함수를 피처 맵의 모든 요소에 적용한다.
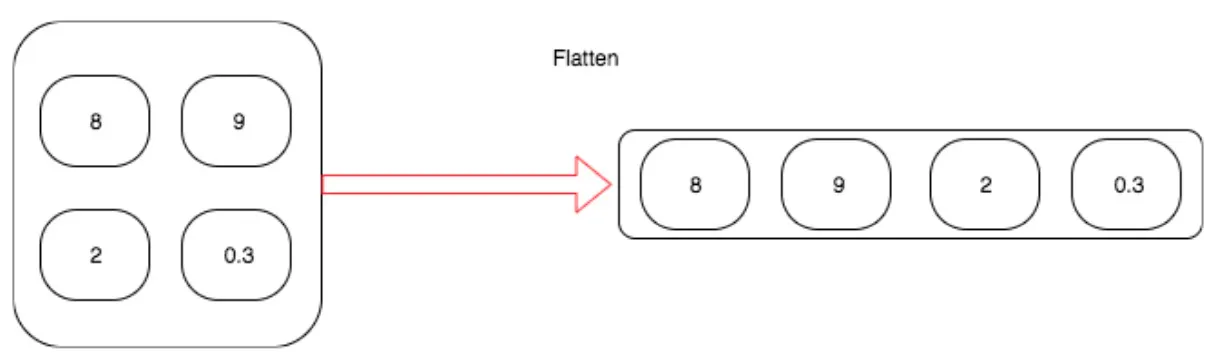
뷰
컨볼루션의 출력을 선형 레이어에 연결하기 위해 2차원 텐서를 1차원 벡터로 변형해야 한다.
단편화
View 메서드는 n차원을 1차원 텐서로 만든다.
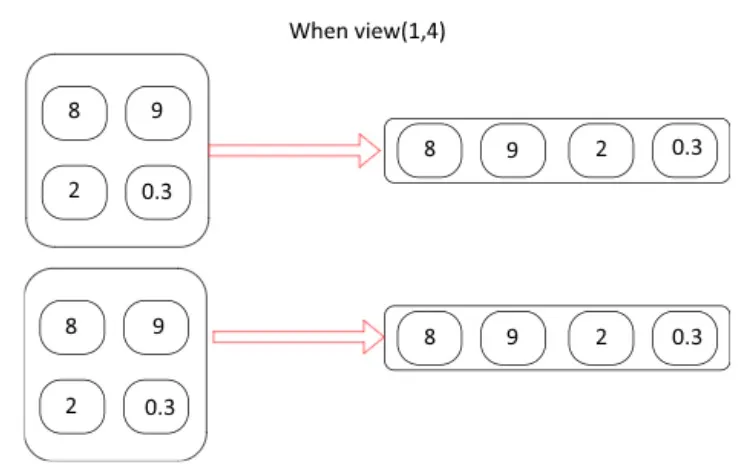
View(2,1,4) 변환 → 배치 크기가 2이고, 높이가 1, 폭이 4로 표현
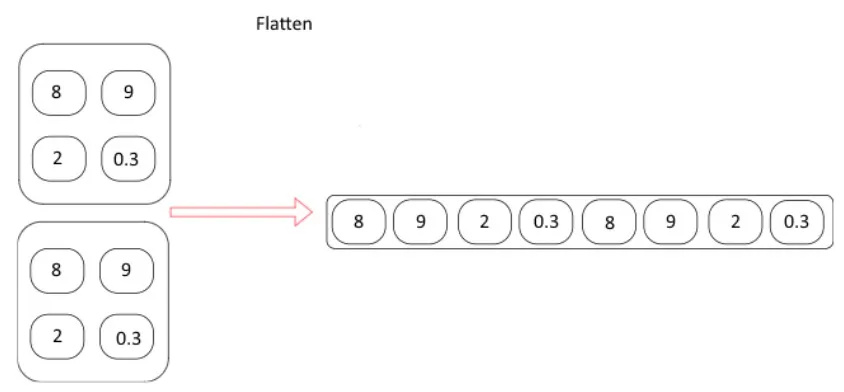
View(-1,8) 표현
선형 레이어
2차원 텐서를 1차원 텐서로 데이터를 변환한 후, 데이터를 선형 레이어에 전달한다.
그 출력을 다시 비선형 레이어에 전달한다.
모델 학습
fit 메서드 : 특정 에폭에 대한 모델의 오차와 정확도를 반환한다.
•
학습 모드에서는 드롭 아웃을 적용해 일정 비율의 값을 제거한다. 드롭아웃은 검증 또는 테스트 단꼐에서는 적용하면 안된다.
•
학습모드의 경우, 기울기를 계산하고 모델의 파라미터 값을 변경한다. 그러나 검증 및 테스트 단계에서는 이러한 역전파를 수행하고 파라미터를 변경하는 작업이 필요없다.
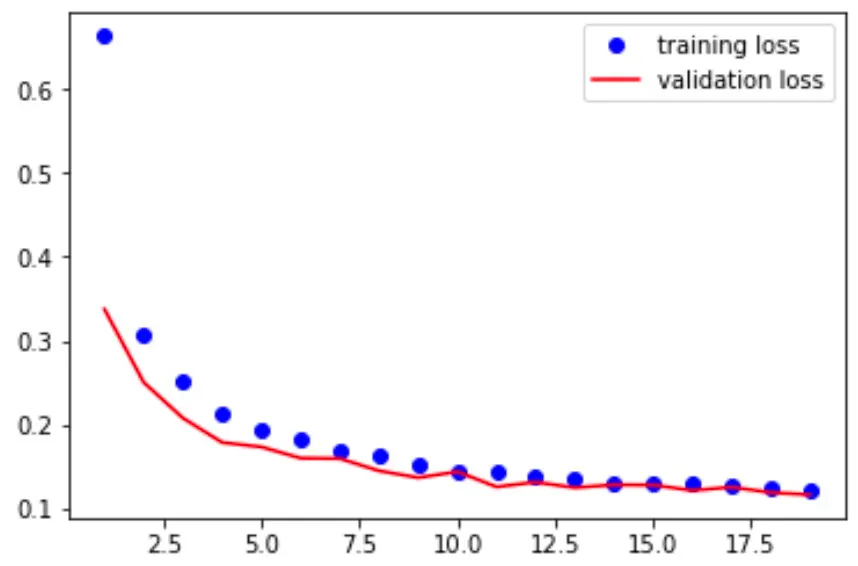
fit 메서드를 20번 반복해 모델을 학습시키고 난 오차 그래프
CNN을 이용한 분류
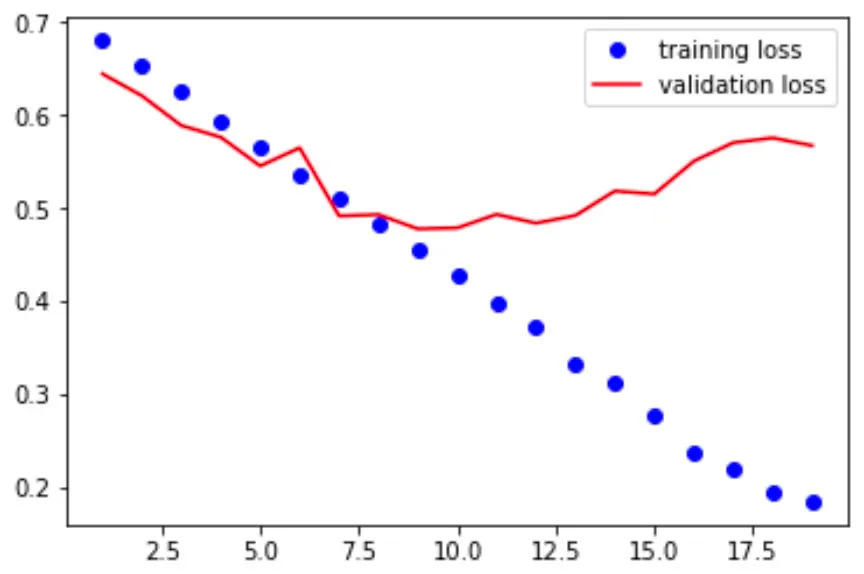
학습이 반복될 때 마다 학습 오차는 감소하지만, 검증 오차는 그렇지 않음.
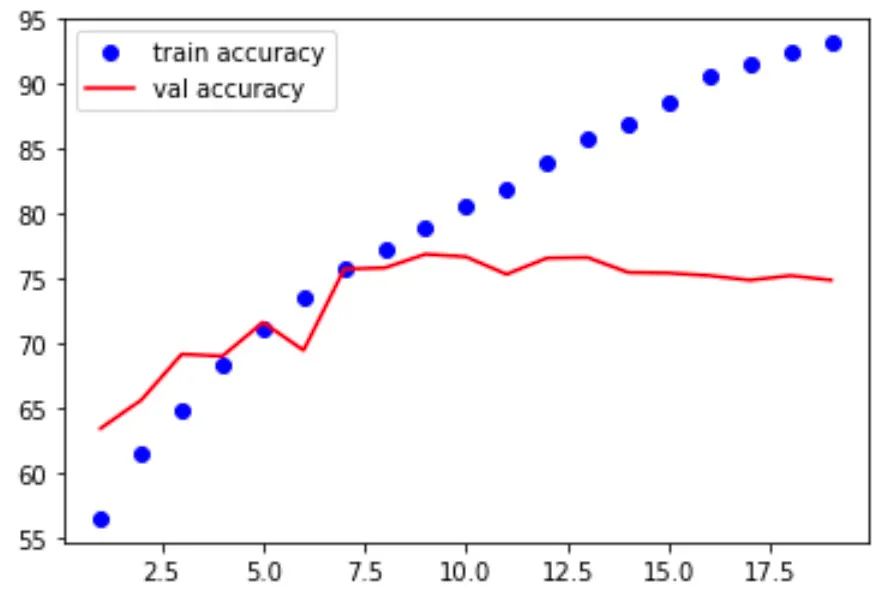
학습이 진행됨에 따라 학습 데이터 셋의 정확도는 증가하지만, 검증 데이터셋의 정확도는 증가하고 있지 않다.
전이학습을 이용한 분류
전이 학습은 사전에 학습된 알고리즘을 유사한 데이터셋에 재사용하는 기능이다.
전이 학습을 사용하면 새로운 데이터셋을 처음부터 학습하지 않아도 된다.
CNN 학습의 해석
1. 중간 레이어의 출력 시각화
각 레이어의 출력을 활성화라고 한다.
파이토치는 register_forward_hook 이라는 메서드를 제공한다.
이 메서드를 사용하면 특정 레이어의 출력을 추출하는 함수를 만들 수 있다.
기본적으로 파이토치 모델은 메모리를 효과적으로 사용하기 위해 마지막 레이어의 출력만을 저장한다.
2. 중간 레이어의 가중치 시각화
모델에서 특정 레이어의 가중치를 얻는 것은 간단하다.
모든 모델 가중치는 state_dict 함수를 통해 엑세스할 수 있다.
state_dict 함수는 딕셔너리 객체를 반환한다.
이 반환 객체로부터 레이어명을 key로 해 가중치를 조회할 수 있다.