지도 학습
분류 문제 Classification Problems | 이미지 분류 |
회귀 문제 Regression Problems | 주가 예측, 경기 점수 예측 등 |
이미지 분할 Image Segmention | 픽셀 단위 분류, 자율주행 자동차에서 카메라로 촬영한 사진에 서 각 픽셀이 어디에 포함돼 있는지를 구분 |
음성 인식 Speech Recognition | 구글 , 시리와 같은 음성 인식 서비스 |
언어 번역 Language Translation | 특정 언어의 음성을 다른 언어로 번역하는 것 |
비지도 학습
데이터에 레이블 또는 목적 변수가없으면 비지도 학습을 통해 데이터를 시각화하고 압축함으로써 데이터를 이해하는 데 유용
Clustering | 유사한 데이터를 함께 그룹화하는데 유용 |
Dimention Reduction | 고차원 데이터를 시각화하고, 데이터의 숨겨진 패턴 찾을 수 있음 |
Machine Learning Parameter
가중치 | 알고리즘 내부에서 사용된다.
옵티마이저에 의해 변경되거나 역전파 과정에서 튜닝된다. |
하이퍼파라미터 | 아키텍처의형태, 구성, 동작방식을 결정한다.
네트워크를 구성하는 레이어 수와 학습률이 대표적인 하이퍼파라미터이다.
일반적으로 수동으로 변경된다. |
Holdout Strategy
1.
단순 홀드아웃 검증
2.
K-겹 검증
3.
반복 K-겹 검증
단순 홀드아웃 검증
전체 데이터셋의 일정 비율을 테스트 데이터셋으로 나눈다.
테스트 데이터 셋을 나눈 후에는 알고리즘과 하이퍼파라미터가 고정될 때까지 테스트 데이터 셋을 알고리즘과 격리 해야 한다.
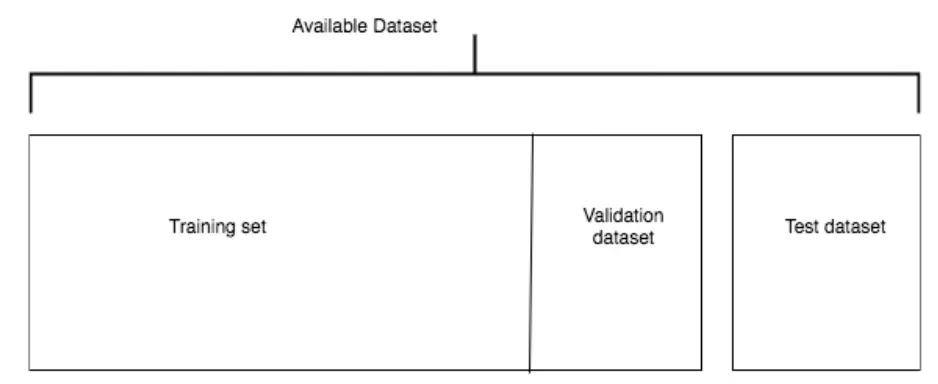
과대적합을 피하기 위해 일반적으로 사용 가능한 데이터를 3개의 데이터 셋으로 나눈다.
K-겹 검증
데이터셋의 일부를 테스트셋으로 나눠 떼어내고, 나머지 데이터를 K개로 균등하게 분할 한다.
K개로 분할한 각 블록을 “겹”이라고 한다.
K번의 학습에서 얻은 모든 점수의 평균을 최종 점수로 한다.

K-겹 검증을 사용하는 알고리즘은 여러 조각으로 나뉜 데이터를 여러번 학습하기 때문에 연산량이 많아진다.
데이터 전처리에서 사용되는 항목
•
Vectorization
•
Normalization
•
Missing values
•
Feature extraction
벡터화
텍스트, 사운드, 이미지 및 비디오와 같은 다양한 형식의 데이터를 파이토치 텐서로 변환
수치 정규화
데이터셋의 특정을 평균이 0이고, 표준편차가 1인 데이터로 만드는 과정

학습 데이터의 특성 정규화는 각 특성을 정규 분포로 만들고 범위를 일정하게 만드는 과정이다.
일반적으로 ‘(특성의 값 - 특성의 평균) / 특성 표준편차’ 공식을 사용한다.
누락 데이터 처리
특성의 빠진 값은 해당 특성에서 발생 할 수 없는 값으로 대체하거나, 해당 특성의평균값, 최빈값, 중앙값, 최솟값, 최댓값으로 대체하는 것이 일반적이다.
특성 공학
머신 러닝 문제의 데이터에 도메인 지식을 적용해 모데렝 전달할 새로운 변수 , 피처를 만다는 프로세스이다.
도메인 지식을 이용하면, 기존 데이터로부터 여러 특성을 추출하고 새로운 파생 특성을 만들 수 있다.
Overfitting , Underfitting
학습 데이터셋에서는 잘 동작하지만, 새로운 데이터셋, 검증 데이터셋, 테스트 데이터셋에서는 잘 동작하지않을 때 과대적합이라고 한다.
과적합 = 학습 데이터셋을 완전히 암기한 상태
과대적합 해결 방법
•
더 많은 데이터 확보
•
네트워크 크기를 줄임 (3개의 선형 레이어 → 2개의 선형 레이어) → 용량 감소
•
가중치 규제 (모델의 가중치가 큰 값을 가질 때, 모델에 불이익을 줘 네트워크에 제약)
◦
L1 규제 : 가중치 계수들의 절댓값 합계를 비용에 추가한다.
◦
L2 규제 : 모든 가중치 계수들의 제곱합을 비용에 추가한다.
옵티마이저의 weight_decay 매개변수로 L2 규제를 적용 가능 (일반적으로 1e-5 와 같은 값 사용)
•
드롭아웃 적용
학습을 진행하는 과정에서 모델의 중간 레이어에 적용
임계값이 0.2로 설정된 드롭아웃을 적용하면, 출력 데이터 중에서 20%를 랜덤으로 선정하고, 선정된 출력에 0을 할당해 모델이 특정 가중치 또는 패턴에 종속되지 않도록 만든다.
nn.dropout(x,training=True)
과소적합 해결방법
•
학습할 데이터를 더 많이 확보
•
레이어 수 추가
•
모델에서 사용하는 가중치 또는 매개변수를 추가
신경망의 마지막 레이어에 사용하는 오차함수 & 활성화 함수
문제 유형 | 활성화 함수 | 오차 함수 |
이진 분류 | 시그모이드 | nn.CrossEntropyLoss() |
다중 클래스 분류 | 소프트맥스 | nn.CrossEntropyLoss() |
다중 레이블 분류 | 시그모이드 | nn.CrossEntropyLoss() |
회귀 | 없음 | MSE |
벡터 회귀 | 없음 | MSE |
가중치 규제 적용
•
드롭아웃 추가 : 실험을 통해 최적의 레이어를 찾는다. 일반적으로 드롭아웃의 비율은 0.2와 같은 작은 값으로 시작한다.
•
아키텍쳐 변경 : 레이어에 활성화, 레이어수, 가중치 크기를 변경할 수 있다.
•
L1 또는 L2 규제 적용 : 2개의 규제 기법 중에 1개를 사용할 수 있다.
•
학습률 변경
•
특성 추가 및 학습 데이터 셋 늘리기
모든 하이퍼파라미터를 조정하기 위해 검증 데이터셋을 사용한다. 하이퍼파라미터를 반복해 조정하는 과정에서 데이터 유출 문제가 발생할 수 있다. 테스트에 사용되는 데이터셋은 홀드아웃 데이터인지 확인.