
•
N-gram의 한계
→ 기존 N-gram은 N-1개의 데이터로 다음 단어를 예측 → 데이터에서 여러 번 입력되어야 하는데 충분한 데이터를 관측하지 못한다면 언어를 정확하게 모델링 할 수 없는 문제가 발생
즉, 단어 간의 유사도를 정확하게 인식하지 못하는 문제가 발생!
ex) I am a man 에서 man 자리에 boy가 나올 수도 있는데 boy가 문장에 없으므로 생각조차 못해버린다.
—> 이런 생각이 word embedding , word2vec의 기본 아이디어.
1.
Neural Network Language Model
-Point : 일종의 NN을 활용한 Word embedding. 유사도에 따른 벡터로 만들기.
구조를 보기전 Word2vec은 1 layer임을 기억해두자.
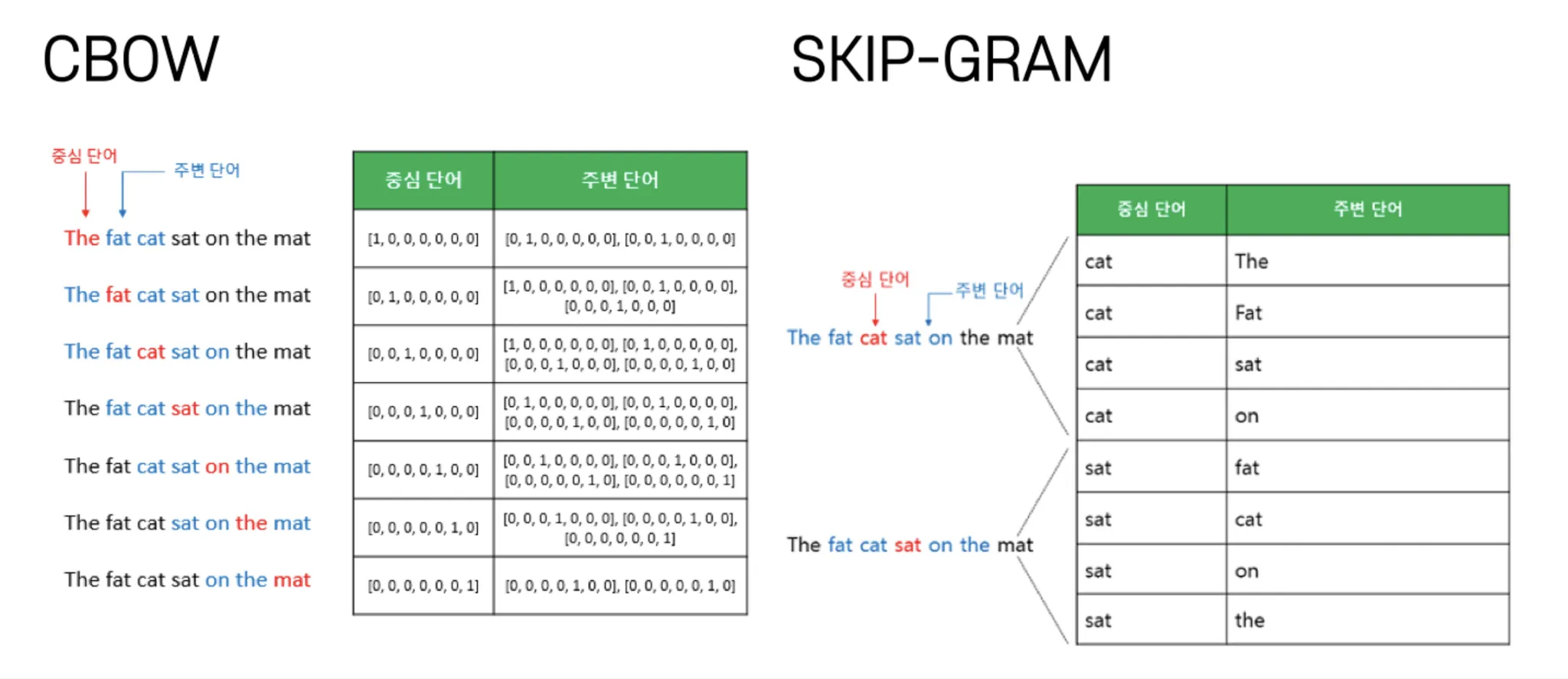
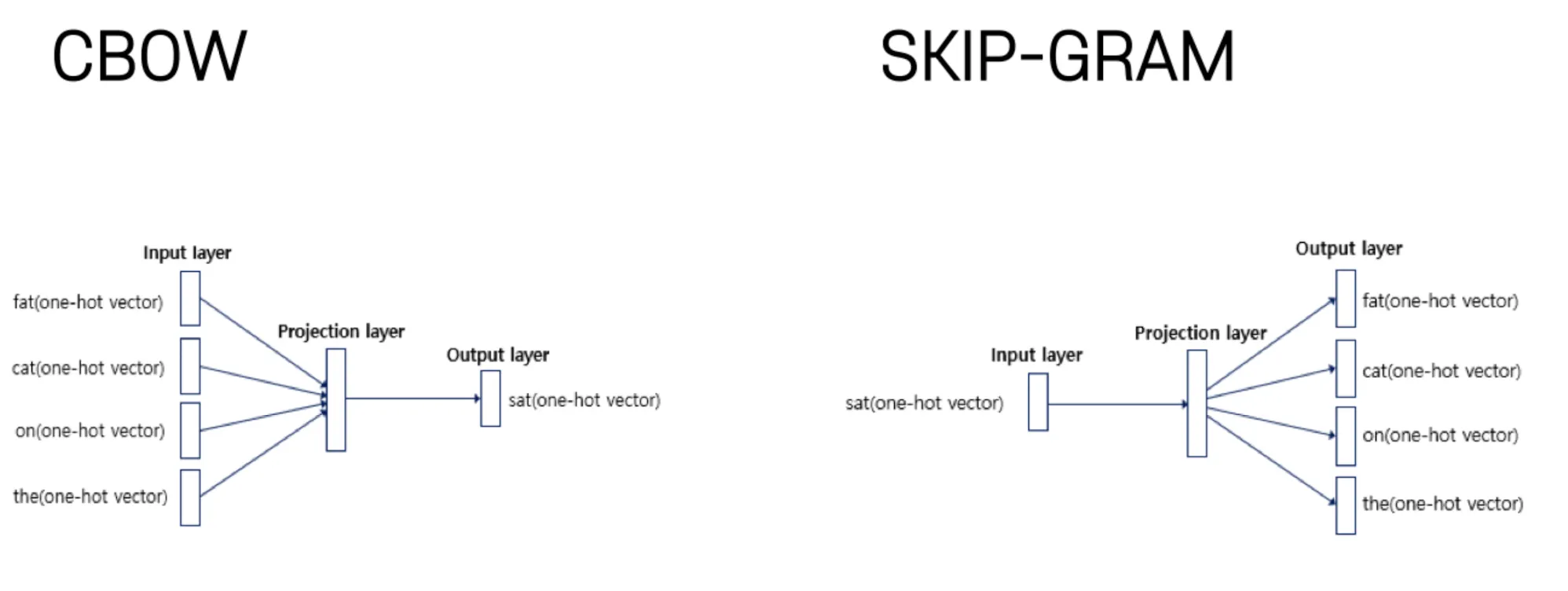
1) CBOW → 주변을 통해 하나를 예측

•
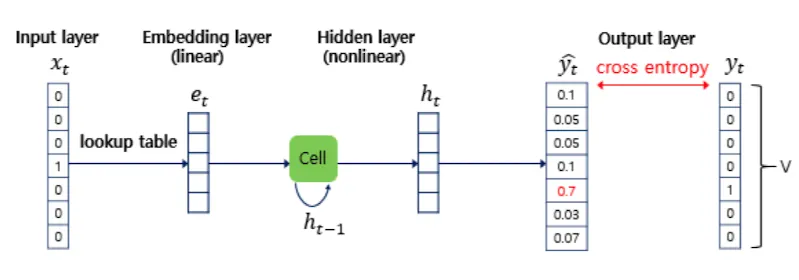
Cross Entropy 로 학습하면 저 노란색이 Embedding Vector 가 된다.
<Why?> 왜 h가 임베딩 벡터가 아니라 그 전의 V가 임베딩 벡터일까?
→ V 는 linear transformation 의 결과라서 단어 간의 linear relationship 을 유지할 수 있다!

•
이 때 Linear 구성의 장점 ⇒ 유사도에 따라 연산이 된다는 점!
2) SKIP-GRAM → 하나를 통해 여러개를 예측
그렇다면 왜 대체 뭐가 word2vec이랑 다른가?
→ word2vec 은 skip gram이 대부분이란 점에서 다르다!
→ word2vec 의 CBOW는 linear 연산, 즉 매트릭스 곱 연산으로만 되어있다.
NNLM은 non-linear 층 , 즉 activation function 이 있는 층이 적어도 하나가 있다.
→ 유사도 반영이 안됨.
<RNN>
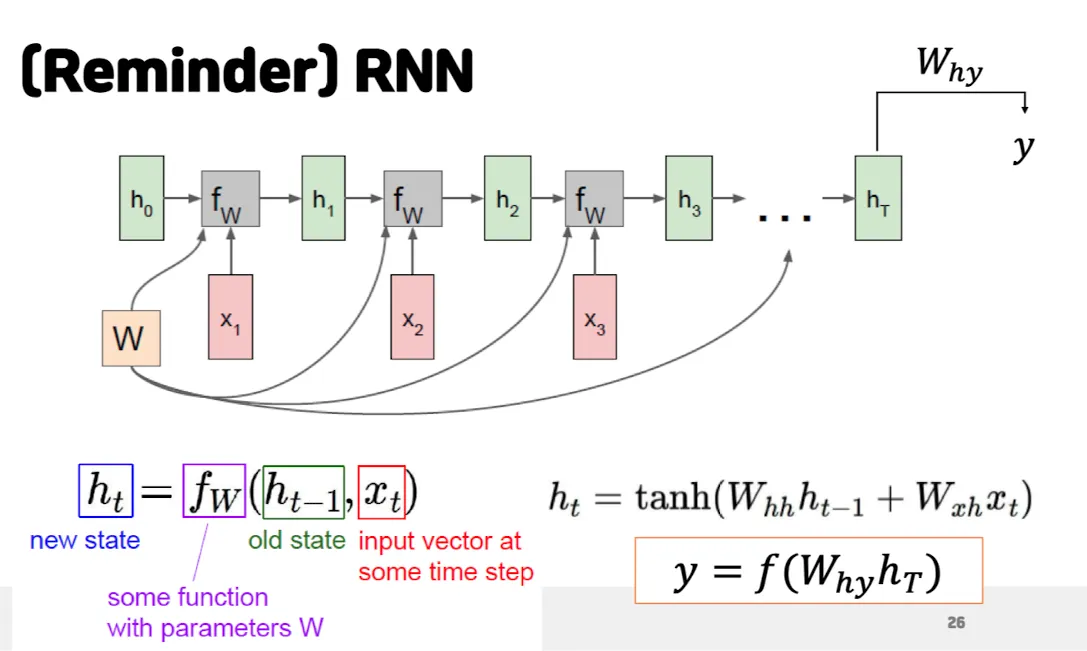
RNN 언어 모델 → NNLM 에 비해 time step 이라는 개념이 존재.
단순한 유사성이 아닌 시간축에 따른 유사성으로 임베딩.
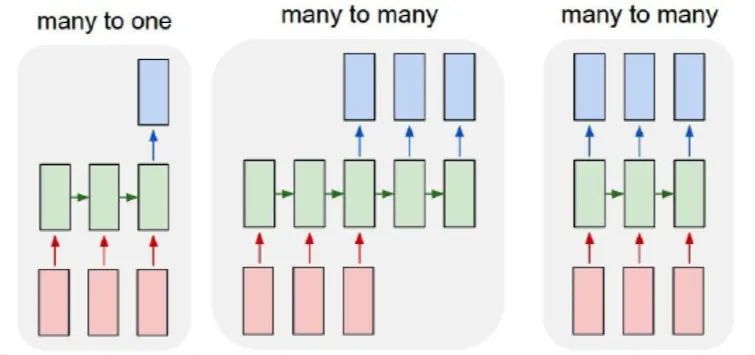
목적에 따라 모델의 구성을 다르게 해야한다는 점!
→ ex) 문장을 통해서 감정을 분류한다 → many to one
→ ex) 기계 번역 → many to many (seq2seq)
•
ELMO
→ Embeddings from Language Model
Context 를 반영한 embedding을 하는 모델
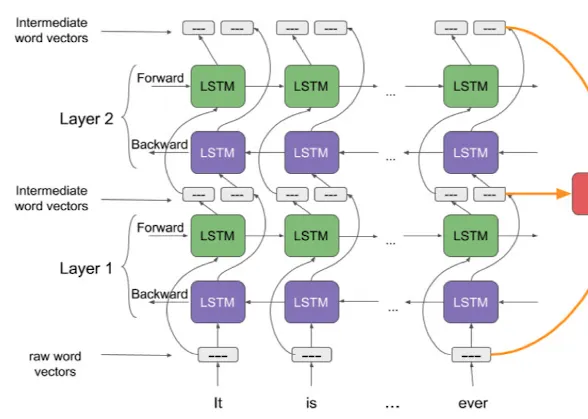
Forward 여러겹 모델 + Backward 여러겹 모델
여러겹을 쌓은 이유 : 기본적으로는 MLP or CNN layer 쌓는 것과 같은 효과
위로 갈수록 더 멀리 연관 정보를 해석 + 서로간의 영향을 주고 받은 결과 반영
•
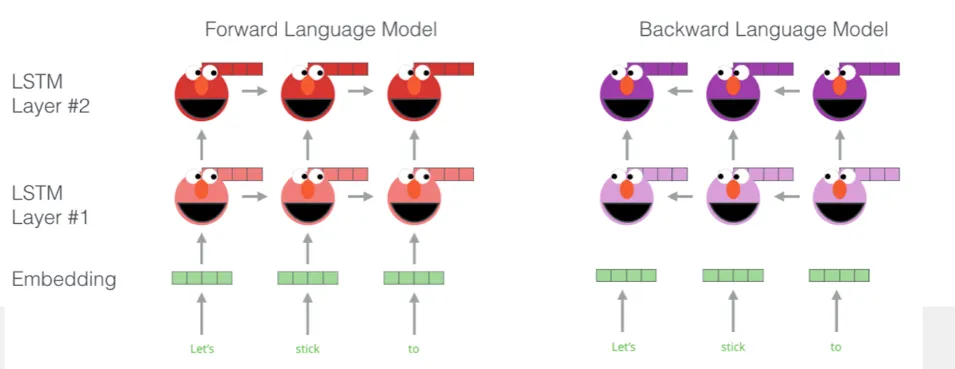
Forward : !다음! 단어를 예측하도록 foward many to one 모델 학습 (그냥 multi layer)
•
Backward: !이전! 단어를 예측하도록 foward many to mone 학습
ELMO란 정방향과 역방향의 hidden state를 모두 활용해서 임베딩 벡터를 만들겠다! 라는 모델