텍스트 데이터 분석
텍스트는 연속된 문자 또는 연속된 단어의 형태를 갖는다.
텍스트 분석할 때 텍스트를 단어의 연속된 형태로 다룬다.
다른 머신 러닝 모델과 마찬가지로 딥러닝 모델도 텍스트 데이터를 직접 이해하기 어렵기 때문에
텍스트를 숫자 데이터로 변환해야 한다.
이 과정을 “벡터화” 라고 한다

텍스트 데이터를 토큰으로 변환할 때, 각 토큰을 하나의 고유한 벡터에 대응시켜야 한다.
가장 많이 사용되는 방법은 one-hot-encoding 과 Word Embedding 이다.
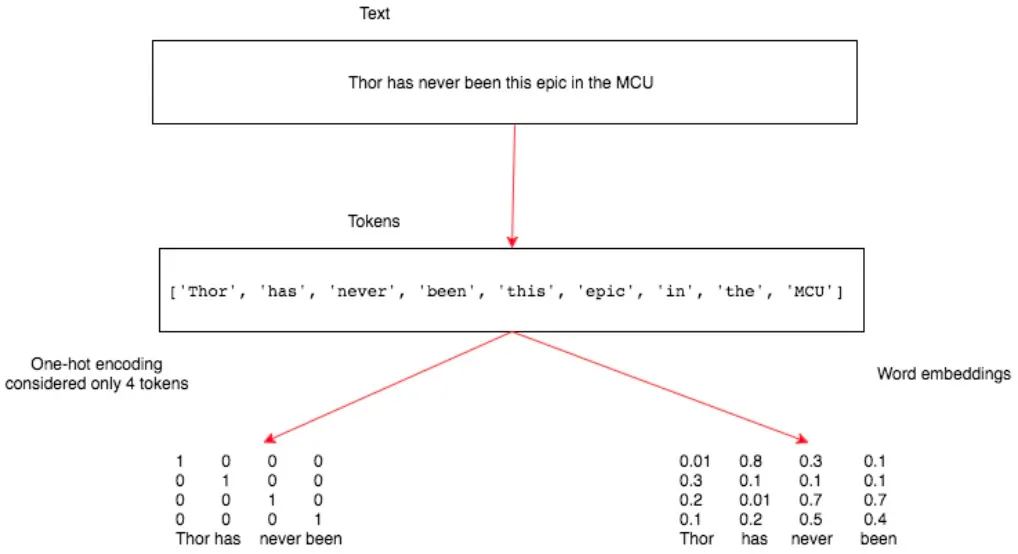
토큰화
주어진 문장을 문자나 단어로 나누는 것
대표적인 라이브러리로 Scipy()가 있다.
split과 list를 이용해 텍스트를 토큰으로 변환할 수 있다.
split → 텍스트를 토큰으로 분할하는 기준이 단어, 공백 문자를 기본값으로 사용
list → 문자열을 개별 문자 목록으로 변환 , 공백 문자도 토큰으로 포함
N-그램 표현
때때로 2개, 3개 그 이상의 단어을 함께 다루는 것이 유용할 때가 있다.
N은 함께 사용되는 단어의 수를 나타낸다. (N이 2이면 바이그램)
N-그램의 단점은 텍스트의 순서 정보를 상실한다.
→ N-그램은 얕은 머신러닝 모델에서 사용한다. RNN이나 Conv1D와 같이 아키텍처가 특성 표현을 자동으로 학습하는 딥러닝 에서는 사용 X
벡터화
One-Hot-Encoding
각 토큰은 길이가 N인 벡터로 표현된다.
N은 어휘의 크기이다.
The dog barked loudly.
The | 1000 |
dog | 0100 |
barked | 0010 |
loudly | 0001 |
제시된 문장은 4개의 고유한 단어로 구성되어 있으므로 벡터 길이는 4 이다.
one-hot-encoding 의 문제점 중 하나는 데이터가 너무 희소하고 어휘의 고유 단어 수가 증가 함에 따라 벡터의 크기가 급격히 커진다는 점이다.
⇒ one-hot-encoding 에서는 대부분의 벡터 요소가 0이므로 희소행렬이다.
→ 딥러닝에서는 one-hot-encoding 이 사용되지 않는다.
Word Embedding
부동 소수점 형태의 수로 채워진 밀집 벡터의 형태를 갖는다.
벡터의차원은 어휘 크기에 따라 달라진다.
one-hot-encoding으로 20000개의 어휘를 표현할 경우, 20000 * 20000개의 숫자를 사용하지만
word embedding 방식으로 20000개의 어휘를 표현할 경우, 20000 * 차원 수의 형상을 갖는다.
word embedding 생성 방법
1.
각 토큰에 대해 밀집 벡터를 생성한다.
2.
각 토큰의 밀집 벡터느 임의의 수로 초기화한다.
3.
문서 분류기 또는 감성 분류기와 같은 방식으로 모델을 학습시킨다.
4.
각 토큰을 표현하는 벡터는 여러 개의 부동 소수점으로 구성된다. (의미가 유사한 단어는 비슷한 벡터를 갖도록 조정)
RNN
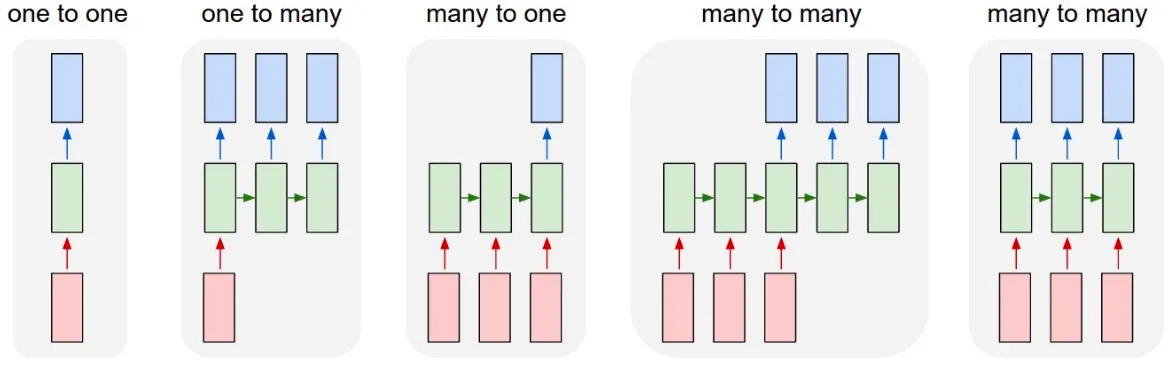
레이블이 있는 순차 데이터를 이용해 다양한 애플리케이션을 만들 수 있는 가장 강력한 모델.
RNN은 한 번에 텍스트의 한 단어씩 보면서 사람과 비슷한 방식으로 작동한다.
기존 신경망 | RNN |
하나의 데이터를 한꺼번에 처리하는 방식 사용 | 하나의 데이터를 순차적이고 반복적으로 처리하는 구조 |
RNN은 순서대로 데이터를 처리하기 때문에 길이가 다른 벡터를 사용할 수 있다.
RNN의 작동 방식
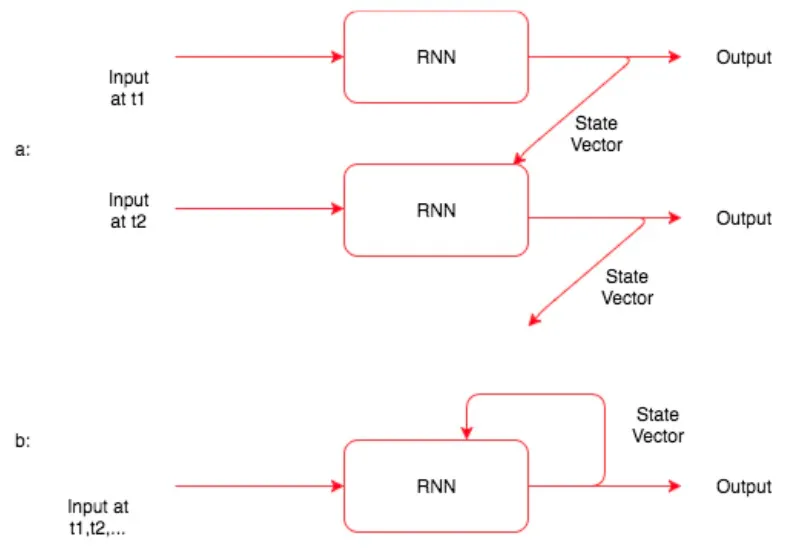
“They watched a movie and ate popcorn in the theater.”
1.
이 문장의 첫번째 단어 They 를 모델에 입력한다.
2.
RNN 모델은 상태 벡터와 출력 벡터를 만든다.
상태 벡터 : 문장의 다음 단어를 처리할 때, 모델에 전달한다 = hidden state (은닉층)
3.
상태 벡터와 새로운 데이터가 결합해 새로운 상태 벡터와 출력 벡터가 만들어진다.
LSTM
RNN은 언어 변역, 텍스트 분류 및 순차적 문제를 해결하는 실제 애플리케이션 구축에 널리 사용되는 알고리즘이다. 그러나 시퀀스가 큰 데이터로 기본 RNN을 학습시키면 vanishing gradients 이나 gradients explosion 과 같은 문제가 발생할 수 있다.
이러한 한계를 해결하기 위해 LSTM이나 GRU같은 알고리즘을 사용한다.
장기 종속성
RNN은 이론적으로 다음에 발생할 일에 대한 context를 구축하기 위해 과거 데이터에서 필요한 모든 종속성을 학습해야 한다. RNN 모델로는 실제로 긴 시퀀스의 앞부분에서 발생한 context를 기억하기 어렵다. LSTM의 내부에 다른 신경망을 추가해 이 문제를 해결.
LSTM 네트워크
장기 의존성 문제를 극복할 수 있게 설계되어, 오랜 기간 정보를 기억하는 것이 가능하다.
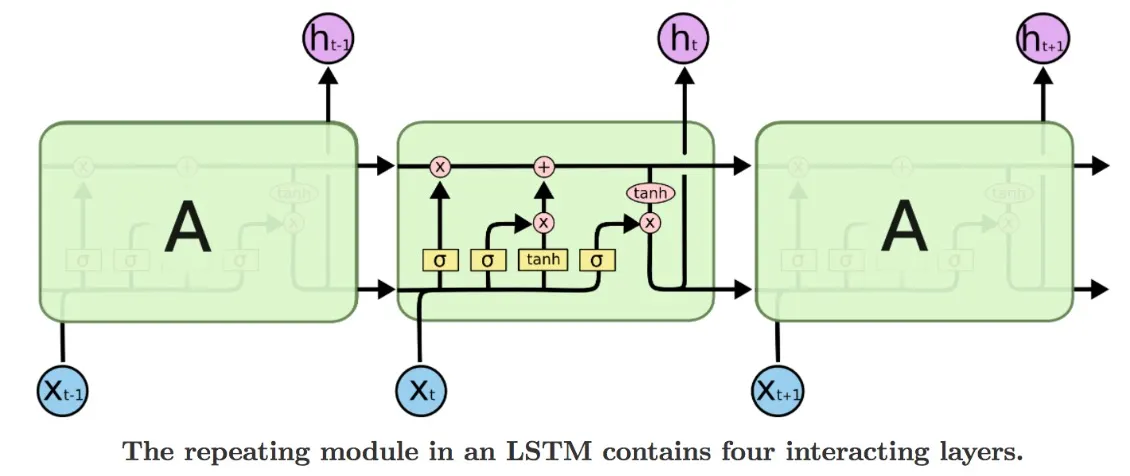
위 다이어그램에서 작은 사각형은 파이토치 레이어를 나태내고, 원은 요소별 행렬 합 또는 벡터 합이다.
합쳐지는 선은 두 벡터가 결합됨을 의미한다.
1.
어떤 정보가 셀 상태에서 제거될지를 결정한다. (이 네트워크를 망각 게이트라고 한다. 이 게이트에서는 sigmoid 함수를 사용한다. 셀 상태의 모든 요소는 0과 1 사이의 값으로 출력한다.)
2.
셀 상태에 어떤 정보를 추가할지 결정한다. (input gate라 불리는 시그모이드 레이어는 업데이트될 값을 결정한다. 셀 상태에 추가할 새값을 만드는 tanh 레이어가 있다.
3.
input gate와 tanh가 만든 두 값을 결합한다.
4.
출력을 결정한다 (출력 : 필터링된 버전의 셀 상태)