
Dynamic Programming
1. Dynamic Programming
•
Substructure
: 기존 문제를 더 작은 하위 문제로 분해
•
Table Structure
: 각각의 하위 문제들을 해결한 후에, 계산된 결과를 table에 저장하여 재사용
•
Bottom-up Computation
: table을 사용하여 하위 문제의 결과를 통합하여 더 큰 하위 문제를 해결하여 결과적으로 기존 문제의 해결책에 도달하는 방식
→ 위의 3가지 방식을 통해 복잡한 문제를 해결한다.
•
DP를 적용하면 유용한 case
1.
Optimal substructure
→ 원래 문제의 optimal solution이 하위 문제의 optimal solution의 결합으로 해결 가능한 상황
2.
Overlapping sub-problems
→ 같은 하위 문제의 해가 반복적으로 필요한 경우 계산량을 줄이기 위해서 table에 저장하여 사용하는 것이 효율적인 상황
⇒ MDP는 Bellman equation에 의하여 재귀적 분해의 요건과 Value function의 재사용이 적용되므로 MDP를 아는 상황에서 DP를 적용하면 MDP를 해결할 수 있다.
2. Sequential Decision Problem
•
Model-based : Planning
MDP를 알고 있는 상황이므로 DP를 이용하여 Planning을 통해 직접 계산하여 문제를 해결한다. 이때 Model에 대한 완벽한 정보를 알고 있기 때문에 직접 계산이 가능하나 방대한 계산량으로 인하여 문제를 더 작은 문제로 나누어 효율적을 계산하기 위하여 DP를 사용한다. 이때 State value function을 주로 이용하며 차원의 저주에 의하여 state space가 너무 크면 제대로 작동하기 어렵다.
•
Model-free : Learning
MDP를 모르는 상황이므로 RL을 사용하여 학습한다. 이때 정확한 transition probability는 모르지만 (s,a) → (s’,a’) 을 여러개 얻으면 근사적으로 transition probability를 파악할 수 있다. 따라서 실제 환경에서 action을 취해서 얻은 sample data로 policy를 평가하여 학습을 진행한다. 이때 모든 state에 대한 계산이 어렵고 주어진 data를 통해 게산해야 하므로 action value function이 주로 사용된다.
⇒ 미래의 state의 value를 통해 현재 state의 value를 update하는 방식을 Backup이라고 하는데, DP에서는 MDP를 아는 상황이므로 full backup을 사용하고 MDP를 모르는 RL에서는 sample backup을 사용한다.
Value iteration
1. Value iteration 개요
Bellman optimality equation을 사용하여 Optimal Policy를 찾는 방법이다. 반복적으로 Bellman optimality equation을 적용하여 Optimal function의 Update가 이전과 변화가 없을 때까지 즉, 수렴시까지 반복하는 방식을 사용한다. 이때 back up 방식에 2가지가 존재하는데, 동기적 방식과 비동기적 방식이다. 동기적 방식은 value function의 update에 update 이전에 계산한 값들을 사용하여 한번에 update하는 방식이고 비동기적 방식은 하나의 state가 update 되면, 나머지에 대해 update가 발생하기 이전에 update를 적용하는 것이다.
2. Value iteration 단점
단점으로는 크게 2가지가 있는데, 각 state가 optimal value에 수렴하기 이전에 value를 max로 하는 action이 거의 정해지게 되므로, 수렴시까지 이를 반복한다면 쓸모없는 연산만 늘어나게 된다. 그리고 각 반복마다 모든 state-action-next state를 고려한 계산이 필요하여 계산량이 으로 상당이 많은 편이다.
*수렴의 의미
→ 모든 state에 대해 update 전/후의 차이가 매우 작다.
3. Algorithm

4. Example
•
Robot Car
아래와 같이 구성된 Robot Car 예시를 통해 value iteration 방식을 적용해보자
1.
State : cool, warm, overheated
2.
Action : slow, fast
3.
Rewards : slow = 1, fast = 2 , overheated = -10
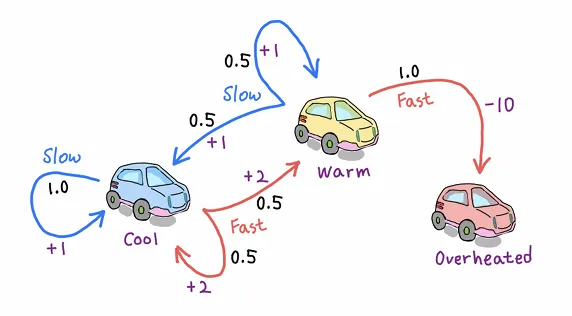
→ transition probability 와 reward를 알고 있으므로 Model-based
•
Value iteration의 적용
1.
각 state value를 0으로 초기화
2.
Bellman optimality equation을 사용하여 optimal state value 계산
3.
수렴 시까지 반복
•
예) 2번째 반복에서 Warm state의 value 계산하기

Policy iteration
1. Policy iteration 개요
Policy iteration은 policy evaluation과 policy improvement를 수렴 시까지 반복하여 optimal policy를 찾아가는 과정으로 Bellman expectation equation을 사용한다. 이때 policy evaluation 단계에서는 deterministic policy를 사용하여 각 state에 대한 value를 수렴 시까지 반복하여 계산한다. 이때 고정된 Policy로 하나의 action만 고려하므로 계산량이 으로 이전의 value iteration에 비해 더 적어진다. Policy Improvement 단계에서는 계산된 state value에 대해 greedy policy를 선택하여 policy를 개선한다.
2. Policy Improvement Theorem

1.
현재 state S에서 Policy 를 따랐을 때의 state value 와 현재 state S에서 Policy 에 의하여 action을 선택하고 이후에 Policy 를 따랐을 때의 action value를 비교했을 때 action value가 모든 state에 대해 크다면 이 더 나은 Policy이다.
2.
현재 state S에서 Policy 을 따랐을 때의 state value와 현재 state S에서 Policy 를 따랐을 때의 state value 중 전자가 크다면, 이 더 나은 Policy이다.

3. Algorithm

→ Iterative policy evaluation을 통해서 를 계산하고 그 결과를 바탕으로 를 선택하여 policy를 개선하는 과정을 반복한다. 이때, 가 에 비해서 뛰어나지 않다면, 두 policy로 계산된 state value가 수렴한 상태가 될 것이고 그때의 value가 optimal value이므로 그때의 policy가 optimal policy가 된다.
→ 반복 횟수가 늘어나야 수렴하게 되는 state-value와 달리 optimal policy는 사전에 정해지는 것이 가능하다. 여기서 value iteration과 다르게 policy iteration은 policy의 개선이 없다면 사전 종료가 가능하다.
4. Optimal policy 정리
•
Dynamic programming
→ Model-based 이므로 MDP에 대한 정보를 알고 있고 따라서 모든 value function의 계산이 가능하므로 table에 value를 저장하여 full backup하는 방식으로 optimal policy를 찾는다. 이 과정에서 계산량의 문제로 state-value function을 주로 사용한다. 또한 DP의 경우 state의 개수가 늘어나면 state에 대해 지수적으로 계산량이 늘어나므로 large problems에는 적합하지 않다.
•
RL
→ Model-free이므로 MDP에 대한 정보를 모르는 상황이기 때문에 환경과 상호작용을 통해 얻은 sample data를 바탕으로 learning을 진행한다. 따라서 근사적으로 Bellman optimality equation을 풀어 optimal solution을 찾는다. sampling을 사용하기 때문에 state의 개수에 대해 차원의 저주에 빠지는 문제를 해결할 수 있다.