
1. Introduction
•
DQN: Approximates the value function using a neural network.
•
REINFORCE: Approximates the policy using a neural network.
•
Actor-Critic: Utilizes both networks — one for the policy (actor) and one for the value function (critic).
2. Actor-Critic
•
REINFORCE
◦
The policy can only be updated after a full episode has finished
◦
Since the gradient is proportional to the return, it exhibits high variance.
•
Actor-Critic
◦
By using an estimator instead of , the update can be performed without waiting for the episode to finish
▪
That helps alleviate the high variance problem.
◦
Therefore, both the critic network parameterized by and the actor network parameterized by are updated.
•
Gradient(AC)
•
Critic
◦
Evaluate the value of the action selected by the actor.
◦
Update in the direction that improves the accuracy of the value estimation
▪
thus aiming to minimize the MSE between the target and the estimated value.
•
Actor
◦
Select an action.
◦
Reflect the critic’s evaluation during the update.
◦
The actor’s objective function is defined with respect to the return, and it is maximized during the update
•
Pseudo Code

1.
Select an action in a given state based on the current parameters.
2.
Apply the selected action and observe the reward and next state.
3.
Using the reward and action obtained in step 2, compute the TD-error and update the critic network through gradient descent.
4.
In this step, MSE of the TD-error is used as the objective function for the critic update.
5.
Reflect the result of the TD-error and update the actor network using gradient ascent.
•
in this pseudocode, it proceeds in a 1-step manner where the update is approximated by the sample mean based on the data obtained from each step.
3. A3C
•
A3C is an actor-critic algorithm that utilizes multiple networks.
•
It consists of a global network and multiple worker agents.
◦
Each worker agent learns independently from environment and asynchronously updates the global network.
◦
Since each agent uses a different policy, it naturally promotes exploration.
•
This independence allows each agent to generate diverse experiences at different time steps
◦
Thereby reducing temporal correlation.
•
In addition, when constructing the advantage function in the critic network, A3C uses the n-step return instead of the Q-function
◦
It increases practicality by allowing the critic to operate with only a single parameterized network.
•
Asynchronous
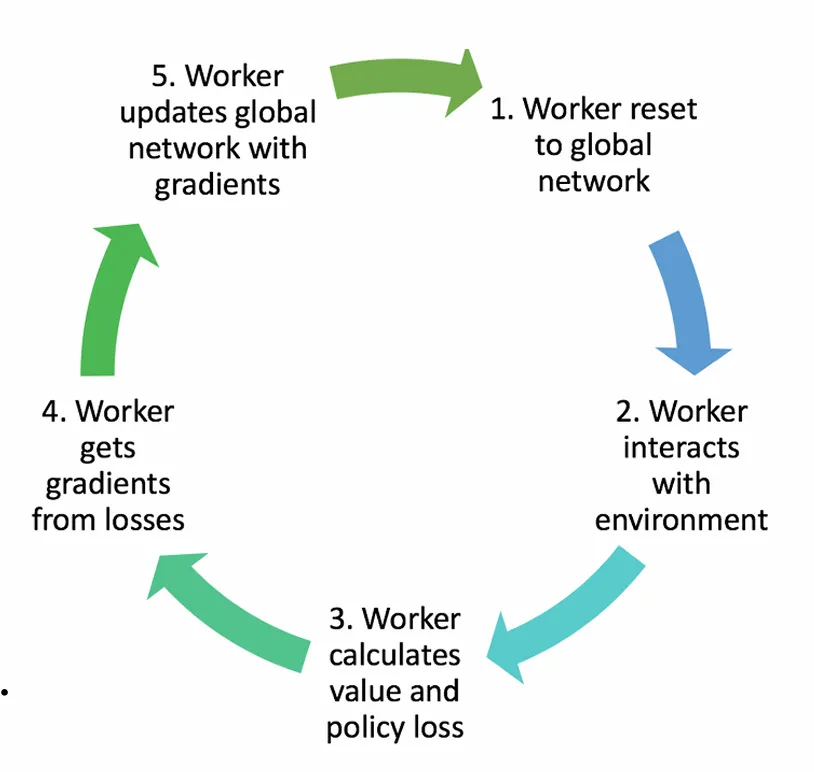
◦
Initialize each worker agent’s parameters by copying them from the global network.
◦
steps while computing gradients.
◦
Asynchronously update the global network parameters using the accumulated gradients.
◦
Copy the updated global network parameters for further use.
◦
As a result, the parameters are reset to include updates made by other workers.
•
Advantage
◦
Various forms of the policy gradient consist of two components: one that contains information about the direction in which the parameters should be updated, and another that determines how much the parameters should move in that direction.
◦
In this term, the advantage function can be used in place of the term that indicates the magnitude of update.
◦
Using the advantage function reduces the variance compared to using the return directly.
◦
However, since it requires two parameterized functions ( and ), the n-step return is used instead of the Q-function.
◦
As the value of increases, the variance of the advantage estimate increases, whereas a smaller results in lower variance.
◦
n-step Return
•
Pseudo Code

1.
Initialize the worker’s network with the parameters of the global network.
2.
steps to obtain a trajectory (worker).
3.
Traverse the time steps in reverse order to compute the n-step return.
4.
Accumulate the gradients for both the actor and critic using the computed n-step returns.
5.
Apply the accumulated gradients to update the global network asynchronously, regardless of whether other agents have finished.